今日はAmazon Bedrock Knowledge Bases のベクトルストアとして Amazon OpenSearch Serverless を指定してウェブドキュメントを取り込む手順を試していきます。
Amazon Bedrock Knowledge Bases とは
Amazon Bedrock が提供する RAG(Retrieval-Augmented Generation)構築用のマネージド機能 です。大規模言語モデル(LLM)に外部データを組み合わせて回答を生成できるようにするための仕組みを簡単に構築できます。
Amazon S3、Amazon OpenSearch、Webサイトなどの外部データをナレッジベースに登録可能です。登録したデータは自動的に ベクトル埋め込み(Embedding) に変換され、検索可能な形式でベクトルストアに保存されます。
データストア と ベクトルストア
Knowledge Bases の設定には2つのデータストアが必要です。Bedrockでは データソース と表記されます。
データストア:ベクトル化される前のデータが格納されているストアですが、S3内部のテキストファイルやWebサイトなども指定可能です。
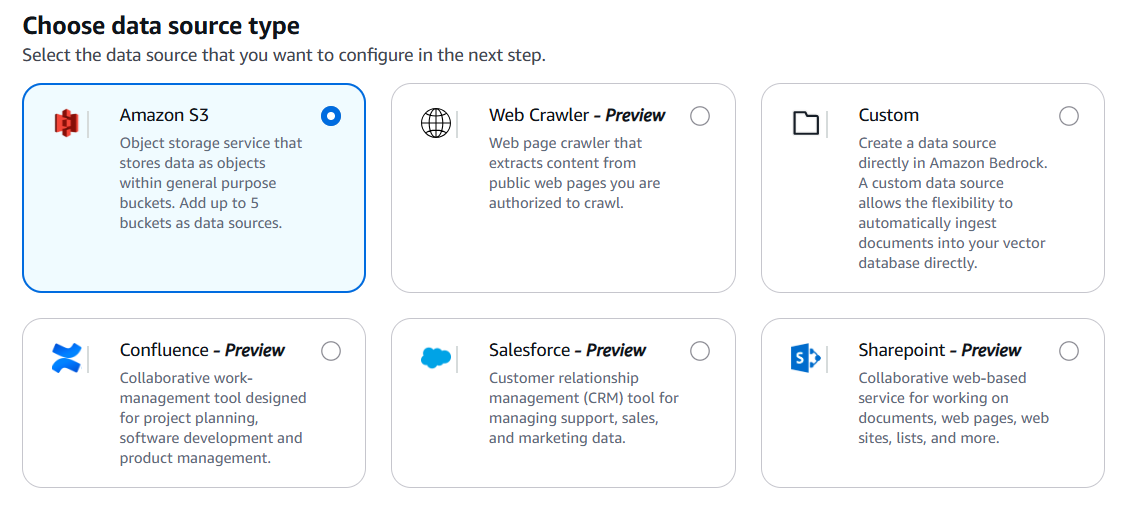
ベクトルストア:データストアのデータを指定した埋め込みモデルでベクトル化したものを保存するストアです。
以下の手順では
データストア:Webサイト (OpenSearch のドキュメント)
ベクトルストア:OpenSearch Serverless
を試していきます。
さっそくやってみる
1.Bedrock Knowledge ベースの作成
Bedrock マネージメントコンソール左ペインで、 ナレッジベース を選択し、 作成 をクリックします。

ベクトルストアを含むナレッジベース をクリックします。
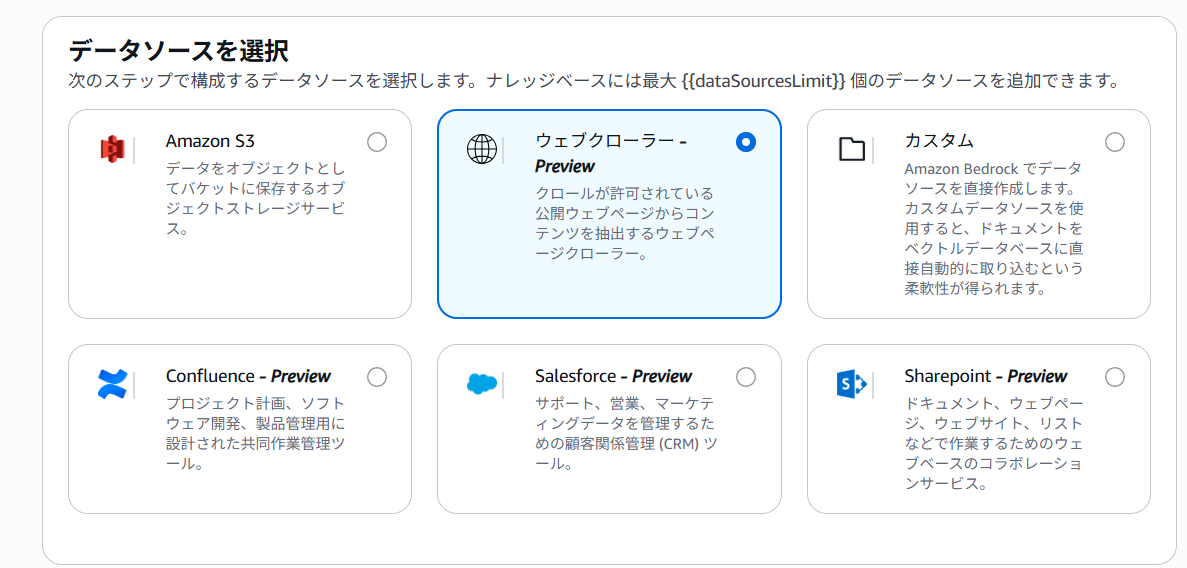
ウェブクローラー を選択し、その他の情報はすべてデフォルトのまま 次へ をクリックします。
ソースURL にOpenSearch ドキュメントのURLを指定します。
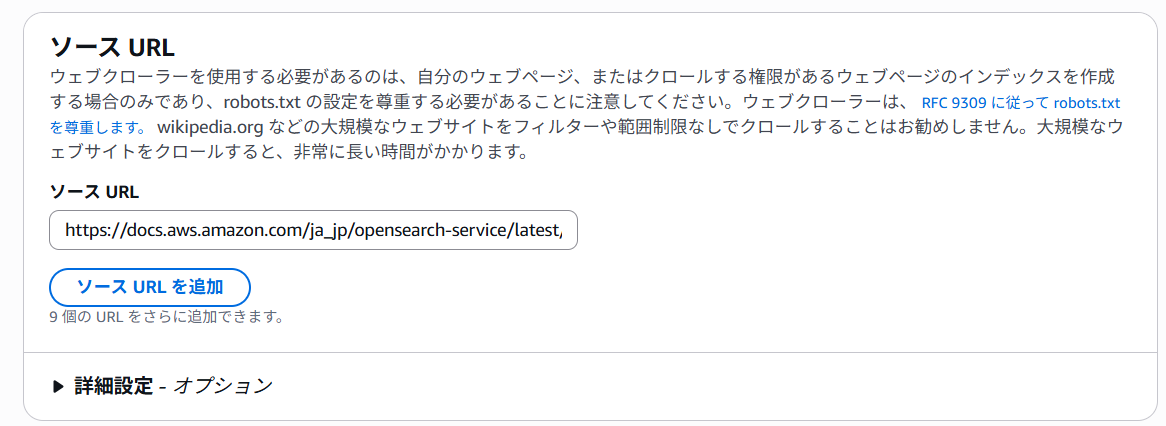
テスト用に大量のドキュメントをクローリングしてしまわないよう 10 と制限し、 次へ をクリックします。

埋め込みモデル は Titan Text Embeddings V2 を選択します。
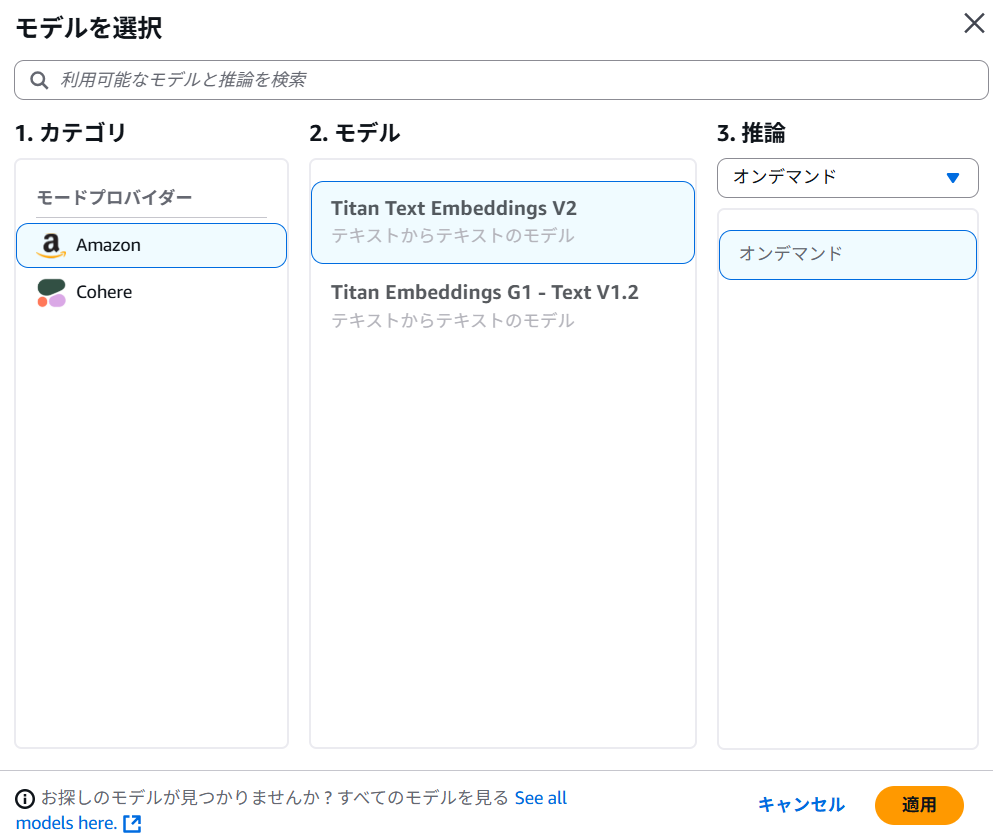
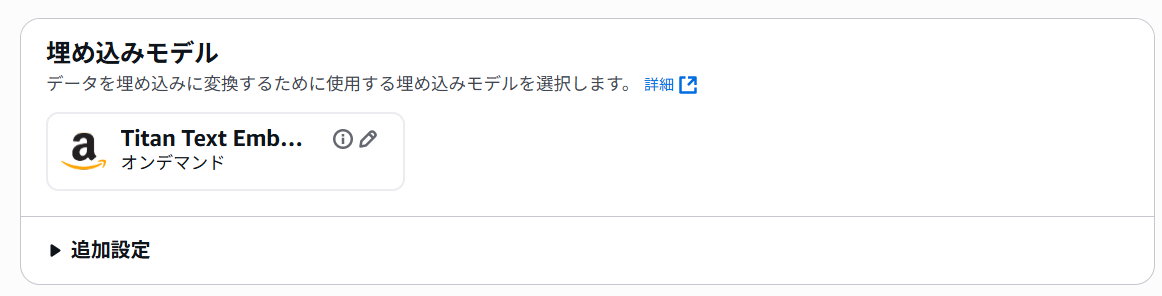
ベクトルデータベース は OpenSearch Serverless を指定して、 次へ をクリックします。
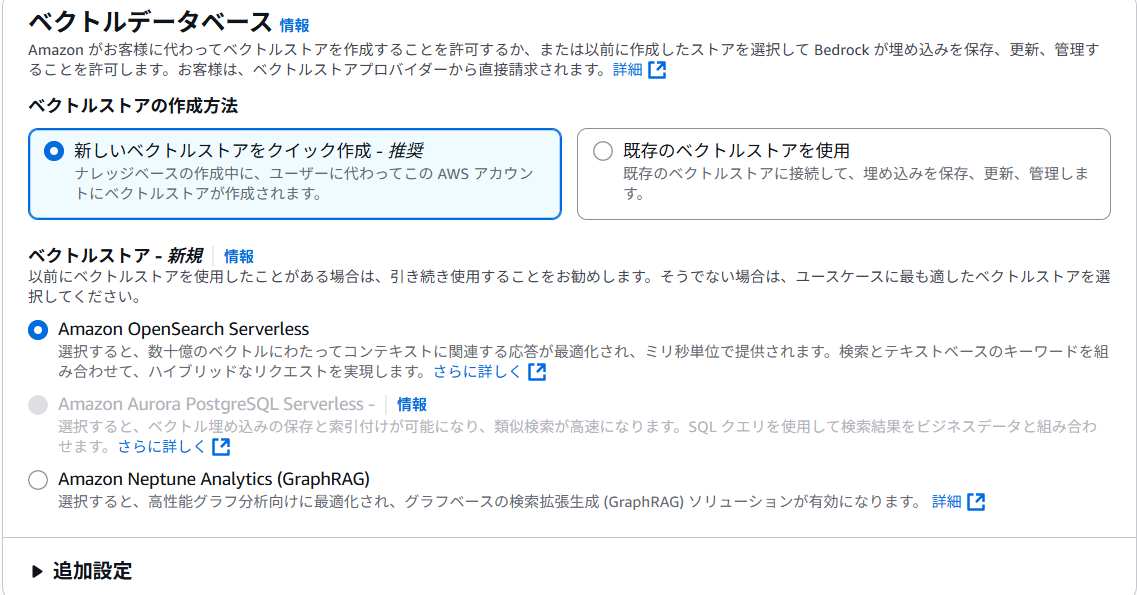
最後の画面で ナレッジベースの作成 をクリックして数分待ちます。
2.OpenSearch Serverlessの確認
作成が完了したらBedrock側から自動でOpenSearch Serverlessが作成されます。

インデックスが一つできています。
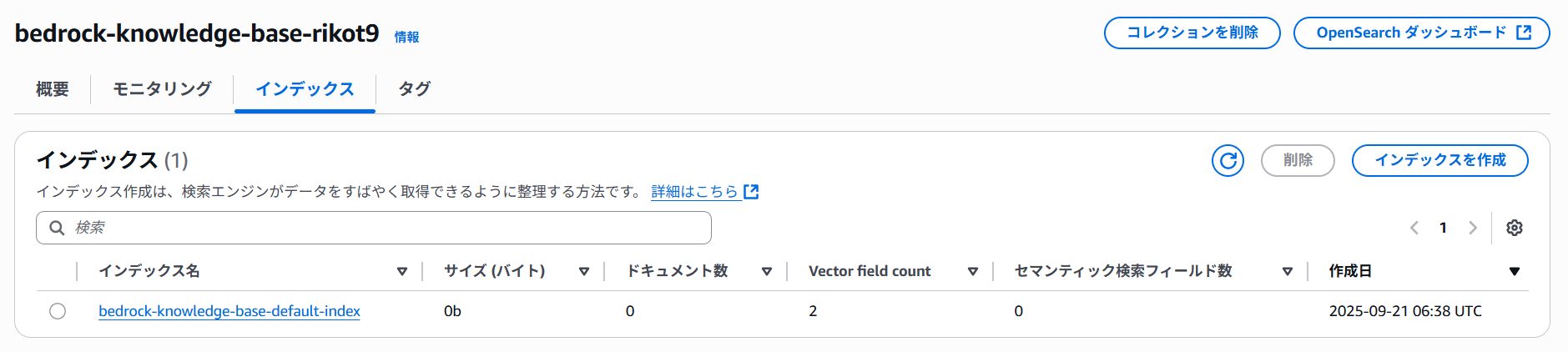
管理用ダッシュボードで以下のコマンドを実行します。
GET /bedrock-knowledge-base-default-index{
"bedrock-knowledge-base-default-index": {
"aliases": {},
"mappings": {
"dynamic_templates": [
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"fields": {
"keyword": {
"ignore_above": 2147483647,
"type": "keyword"
}
},
"type": "text"
}
}
}
],
"properties": {
"AMAZON_BEDROCK_METADATA": {
"type": "text",
"index": false
},
"AMAZON_BEDROCK_TEXT_CHUNK": {
"type": "text"
},
"bedrock-knowledge-base-default-vector": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"engine": "faiss",
"space_type": "l2",
"name": "hnsw",
"parameters": {}
}
}
}
},
"settings": {
"index": {
"number_of_shards": "2",
"provided_name": "bedrock-knowledge-base-default-index",
"knn": "true",
"creation_date": "1758436699878",
"number_of_replicas": "0",
"uuid": "xCT-apkB74rdMqtsrtPQ",
"version": {
"created": "136387827"
}
}
}
}
}無事Indexが登録されていることがわかります。インデックスは以下のコマンドで検索できます。現時点ではデータが空欄であることを示す結果が戻ってきます。
GET /bedrock-knowledge-base-default-index/_search{
"took": 20,
"timed_out": false,
"_shards": {
"total": 0,
"successful": 0,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}3.データ取り込み
ではKnowledge Basesにデータを取り込みます
先ほど作成されたデータソースの画面から 同期 ボタンをクリックします。
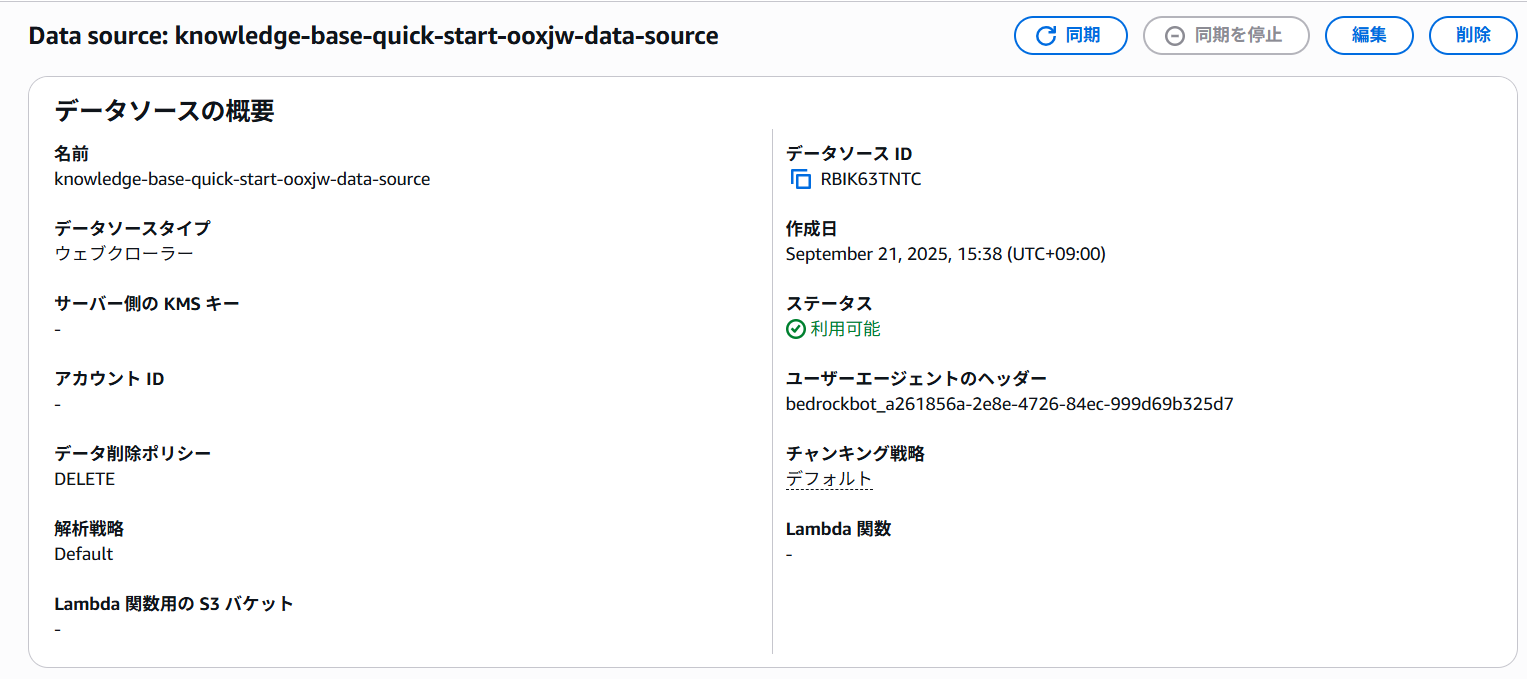
データの取り込みが開始されますので、しばらく待ちます。

4. データ検索
取り込みが完了したらデータ検索を行います。まずはOpenSearch Serverless のDevToolから以下のコマンドを実行します。
GET /bedrock-knowledge-base-default-index/_search{
"took": 84,
"timed_out": false,
"_shards": {
"total": 0,
"successful": 0,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5238,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "bedrock-knowledge-base-default-index",
"_id": "1%3A0%3ANEoOa5kBGTQlPq8G36iP",
"_score": 1,
"_source": {
"x-amz-bedrock-kb-source-uri": "https://docs.aws.amazon.com/ja_jp/opensearch-service/latest/developerguide/opensearch-service-dg.pdf",
"AMAZON_BEDROCK_TEXT": "............................................................................. 15 インデックス作成のためにデータをアップロードする ................................................................. 17 オプション 1: 単一のドキュメントをアップロードする .......................................................... 17 オプション 2: 複数のドキュメントをアップロードする .......................................................... 18 ドキュメントの検索 ....................................................................................................................... 19 コマンドラインからドキュメントを検索する .......................................................................... 19 OpenSearch Dashboards を使用してドキュメントを検索する ............................................... 20 ドメインの削除 .............................................................................................................................. 21 Amazon OpenSearch Ingestion ......................................................................................................... 22 主要なコンセプト .......................................................................................................................... 22 利点 ................................................................................................................................................ 24 制限 ................................................................................................................................................ 24 サポートされている Data Prepper のバージョン ......................................................................... 25 パイプラインのスケーリング ........................................................................................................ 25 料金 ................................................................................................................................................ 27 サポートされる AWS リージョン ................................................................................................. 27 ロールとユーザーの設定 ................................................................................................................ 27",
"x-amz-bedrock-kb-document-page-number": 3,
"AMAZON_BEDROCK_METADATA": """{"source":"https://docs.aws.amazon.com/ja_jp/opensearch-service/latest/developerguide/opensearch-service-dg.pdf","sourceType":"WEB"}""",
"x-amz-bedrock-kb-data-source-id": "RBIK63TNTC",
"bedrock-knowledge-base-default-vector": [
-0.029882366,
0.026826214,
0.019808386,
-0.005235073,
<snip>「5238 件のドキュメント断片(チャンク)がインデックス化されていることが確認できます
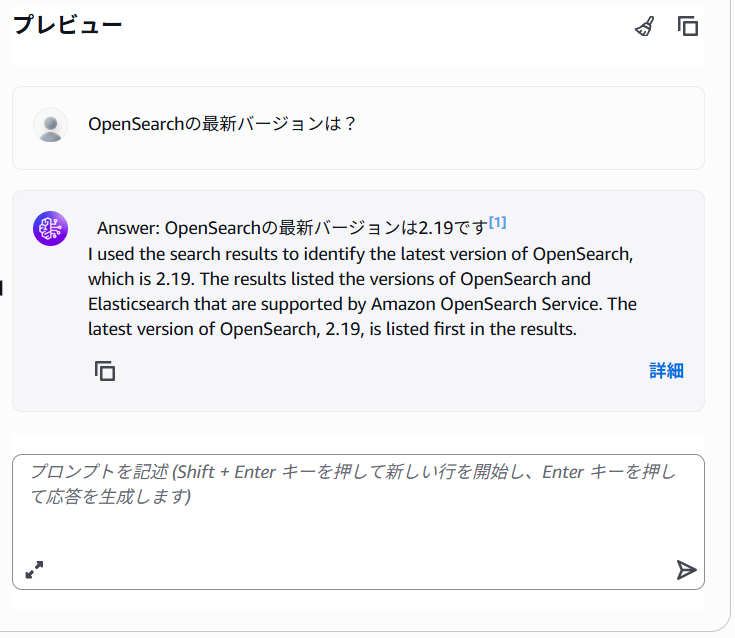
ナレッジベースをテスト をクリックします。
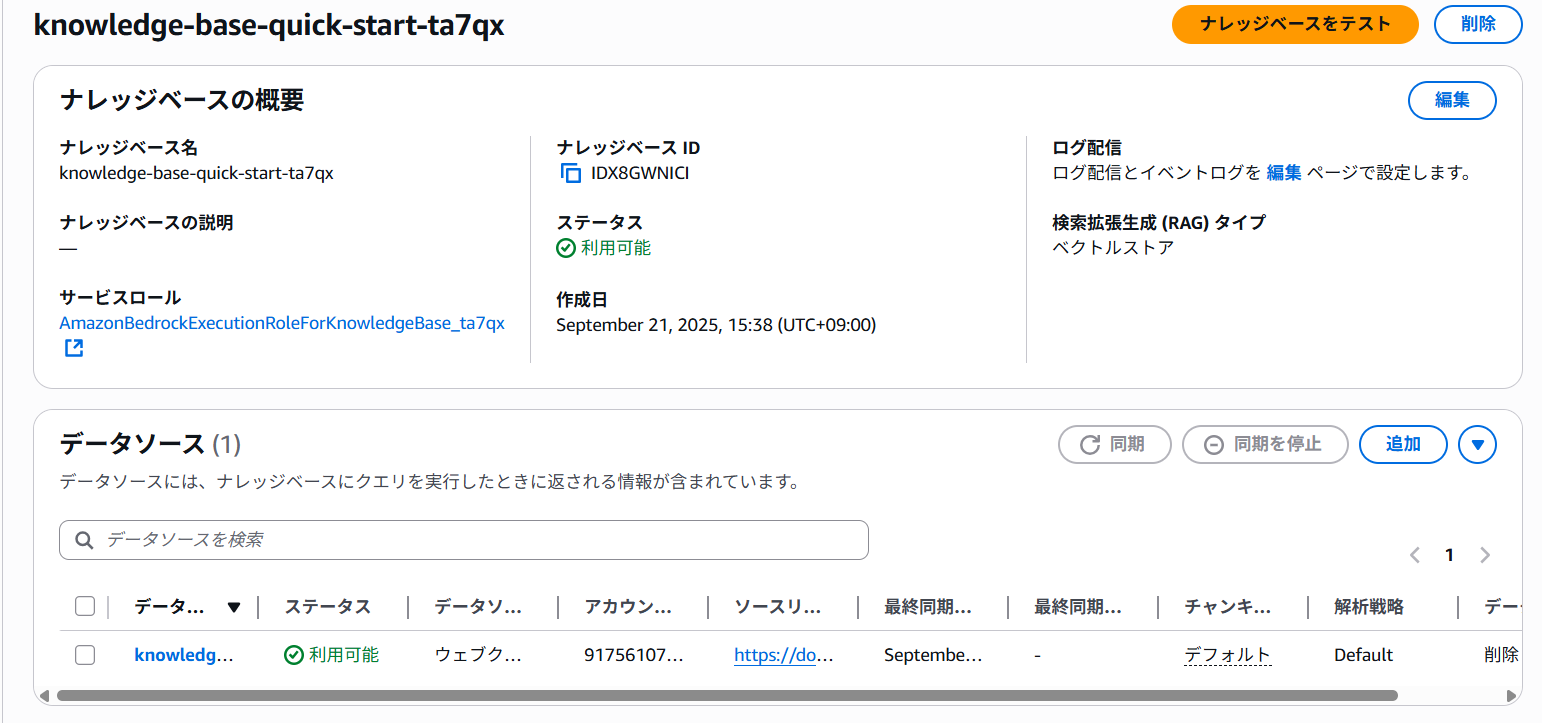
RAGにつかうモデルを選択して対話を行ってみます。
無事検索が完了しました!この状態で LLM に質問すれば、OpenSearch に格納されたドキュメントを根拠に回答が返ります。