

大規模言語モデルで採用されているScaling Lawについて
「Law(法則)」という単語は日本語で「〜の法則」と訳されることが多いですが、ここで扱うScaling Lawはスケーリングの法則と訳すと直感的に理解しやすいかもしれません。
多くの人が聞いたことのあるシンプルな説明としては、「学習パラメータとデータ量を増やせば、正しい回答が返ってくる可能性が高まる」というイメージです。ただし、これはあくまで分かりやすい表現であり、厳密には正しくありません。正確には、パラメータ数、データ量、そしてコンピューティングリソースを増やすほど、言語モデルが予測する確率分布から外れた損失(エラー)が発生する確率が大幅に減少するということを指しています。
つまり、「間違った回答をする可能性が低くなる」からこそ、最終的に我々が求める正しい回答を得られるのです。この関係性を示すものとして有名なのが、OpenAIが発表した論文にある以下のグラフです。Scaling Law の理解を深めるうえで、代表的な図としてしばしば引用されます。
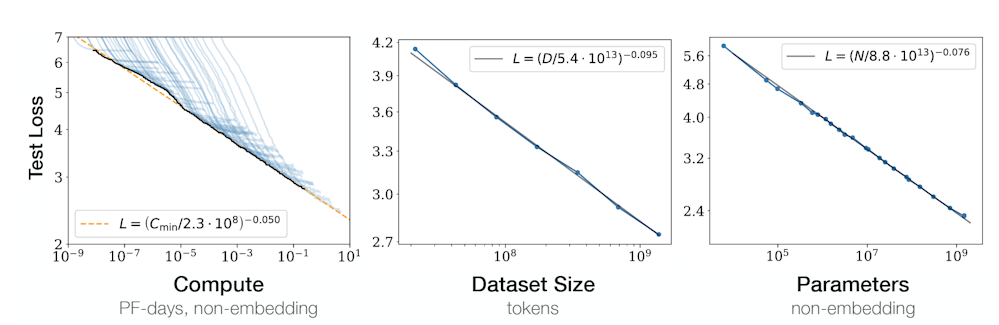
しかしながら、パラメータ数・データ量・コンピューティングリソースを際限なく増やし続けることには限界があります。確かに、それらを増やせば損失(loss)は減少しますが、その改善幅は次第に小さくなり、やがて費用対効果が見合わなくなってしまいます。加えて、すでにWeb上の高品質な学習データはほぼ使い尽くされているとも言われています。もし無理に低品質なデータを追加すれば、かえってLLMの品質を損なう可能性すらあります。
Densing Lawについて
これは密度の法則と訳せば良いかもしれません。ポイントとしては、スケーリングの法則がパラメータの数に着目しているのに対して、密度の法則はパラメータの密度に着目しています。これだけだと何のことだかわからないと思いますが、簡単に図にしてみると以下のようなイメージです。
.png)
Scaling Law は、モデルが膨大なテキストの塊から次に来る単語を確率的に予測しています。一方で Densing Law は、実際にユーザーがプロンプトを入力して、それで得られる回答から必要なパラメータ数(有効パラメータサイズ)を逆算しています。そして、そのモデルの実際のパラメータ数と有効パラメータサイズを比較することでモデルの効率(密度)を定義しています。このことは、今後のLLM開発が「巨大化」ではなく、用途に応じた小型化と高効率化へ向かう可能性を示しています。
Densing Lawの研究アプローチ
自分達が基盤モデルを活用して取り組む実用的な課題(QA・要約・分類・翻訳など)は、論文中で 「downstream tasks(下流タスク)」 と呼ばれています。
通常の言語モデルは「次の単語を予測する」タスクで学習され、入力文全体をどれだけ正しく再現できるかで性能を評価します。しかしこの方法は、現実の利用シーンとは少しずれています。実際のユーザは「命令(instruction)」を入力し、モデルは「回答(answer)」を返すからです。したがって、この条件下での関係を評価しなければ、本当の性能は測れません。
そこで論文では、新たに「Conditional Loss(条件付き損失)」を定義しました。これは、入力が与えられたときに正しい答えを返す確率を測るものです。従来のScaling Law とは異なり、答えの正しさそのものに焦点を当てています。
さらに、あるモデルMが性能Sを示したとき、その性能を基準モデルで達成するために必要なパラメータ数を逆算しました。これを有効パラメータサイズ(Effective Parameter Size)と呼びます。そして、これを実際のパラメータ数で割った値がDensity(密度)です。

論文では様々なオープンソースのLLMを対象にこのDensityを算出したところ、密度は約3か月ごとに2倍のペースで増加していることが確認されました。つまり、従来と比べて半分のパラメータで同等の性能を実現できています。これは、データのクリーニングや学習手法の改善によって、LLMの効率が飛躍的に向上していることを示しています。
そしてここで重要なのは、LLM自体の効率(パラメータ密度)は急速向上し、今後は同じサイズのデバイスのチップの上でもより多くのパラメータを詰め込むことで短期間でLLMが効率よく情報を保持・計算できるようになっていくということです。
まとめ
このように言語モデルが小型化・高効率化していくことで、スマートフォンやスマートウォッチといった日常的なデバイスから、小型のIoTデバイスに至るまで、さまざまな環境でLLMを直接デプロイできる未来が訪れるでしょう。あらゆるシーンにおいて、生産性の向上や新しい体験の創出が期待できます。
さらに、OCRのように特定用途に特化した軽量LLMも登場し、安価かつ手軽に利用できるようになることで、より幅広い分野への普及が加速すると考えられます。