

はじめに
この記事の対象としては一般のウェブアプリケーションサービス開発・運用の業務従事者を想定し、 MCP の概念について可能な限り分かりやすく、汎用的な観点で説明するための記事です。技術観点での重要事項や定義については別途記事で触れていきますので、ご参考ください。
MCP を理解するために必要な基礎概念
MCPが何かを理解するためには以下の3つの要素について正しく理解しておく必要があります。まずはこれらについて整理していきましょう。
- 「RAG」とは何か
- 「AI エージェント」とは何か
- 「ツール」とは何か
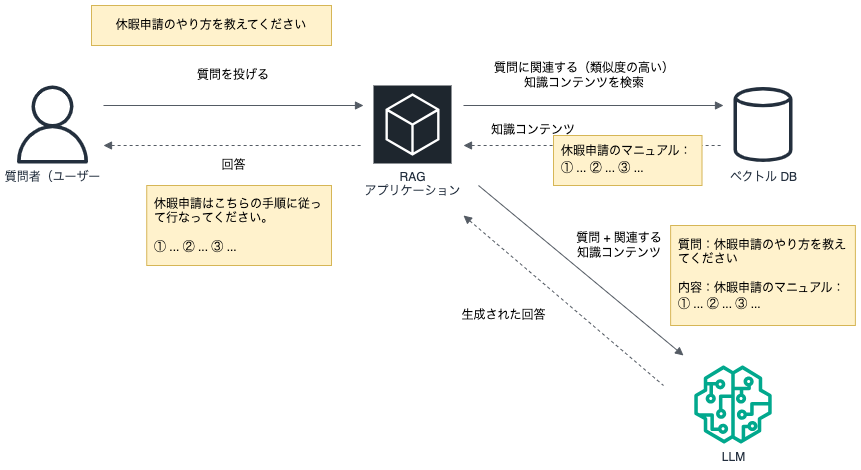
RAG (Retrieval Augmented Generation) とは何か
RAGを一言で表すと"外部情報を検索して情報を検索し、その結果をもとに回答を生成させる手法" と定義づけることができるでしょう。そのためには、予めAIに回答してほしい情報を保存しておき、質問(インプット)に対する関連情報を検索する必要があります。LLM(大規模言語モデル)を利用するうえでよくあるユースケースの一つがチャットボットです。質問に対する回答を、与えられた情報源から検索しチャットボットが人間にわかりやすく回答するシステムです。しかし、このアプローチにはどうしても限界があります。特に重要なのがこのアプローチが「単方向」であるという点です。
単方向であるとはなにか?
ここで言う単方向とは、LLMは自発的に外部システムにアクセスして情報を収集するのではなくて、あくまで質問を受けて回答をする以外のアクションは発生しないという点です。たとえば、ある質問に対して過去のナレッジベースを検索し、その結果をLLMに渡して回答を得るようなケースでは、「検索の必要性を判断する」部分や、「検索結果の要約を含めたプロンプトの組み立て」などはすべてアプリケーション側のロジックで制御する必要があります。LLMはこの一連の流れを“自発的に”行うことはできません。あくまで「渡された内容に対して自然言語で回答する」という役割に徹しているためです。
AI エージェント(AI Agent)とは何か
AIエージェントを一言で表すと“目標達成のために必要な手段を自ら判断・選択し、動的にタスクを実行するアプリケーションサービス”です。当然ながら生成AIを利用するにあたっては質問の回答を得るだけでは物足りないと思うでしょう。有給休暇申請のやり方をチャットに聞いて回答を得るだけでなく有給申請自体までも自動でやってほしいと思うはずです。
そしてこれらを2つの要素に分解すると少しMCPというものがなにか見えてきます。
- RAG(Retrieval-Augmented Generation)
→ 目的に応じて外部データを検索・取り込みながら、正確な回答を生成する仕組み。 - MCP(Model Context Protocol)
→ AIが外部ツールやAPIと連携し、実際に“操作”を実行するプロトコル的な仕組み。
これらを通じて、AIは単なる知識ベースの回答だけでなく、実行主体としての役割も担えるようになります。分かりやすく言えば、例えば以下のような世の中のサービスも広く捉えればAIエージェントのカテゴリに該当すると言えるでしょう。
- ChatGPT(汎用的な知識の受け答え)
- コーディングエディタ(コーディング補助・自動化)
- AI 英会話(英語学習・英語コミュニケーションサポート)
- AI チャットボット(例:サポートセンターの場合、サービス利用における問題解決情報提供)
- AI 自動音声受付(例:サポートセンターにおける各種手続きの音声対応)
※ 厳密には「ワークフロー」と「エージェント」の区分があったりしますが、この記事では MCP を理解しやすくためエージェントという言い方に統一しています。定義の詳細が気になる方は、Anthoropic 公式ブログの「Building effective agents - What are agents?」も合わせてご参照ください。
ツール(Tool)とは何か
ツールを一言で表すと"AI エージェントが目標を達成するために用いる手段"です。以下に具体例をあげます。
- 外部APIを呼び出して必要な情報をアドホックに取得する
- ローカルにあるファイルを読み込み、そのファイルの内容を取得する
- ローカルにあるファイルの作成、修正、削除を行う
- GitHub の Issue / Pull Request / コメントを作成、コードをコミットしたり、マージ・クローズする
- データベースに検索クエリーを投げて結果を受け取る
- 別の AI エージェントに質問を投げる
MCP登場前のAIエージェントの実装
ここまでで「RAG」「AIエージェント」「ツール」について整理を行いました。ここでは、MCPが登場する前はどのようにAIエージェントを作っていたかを見ていきましょう。有給申請を代行するAIエージェントを作るケースでは以下のようなワークフローを実装する必要がありました。
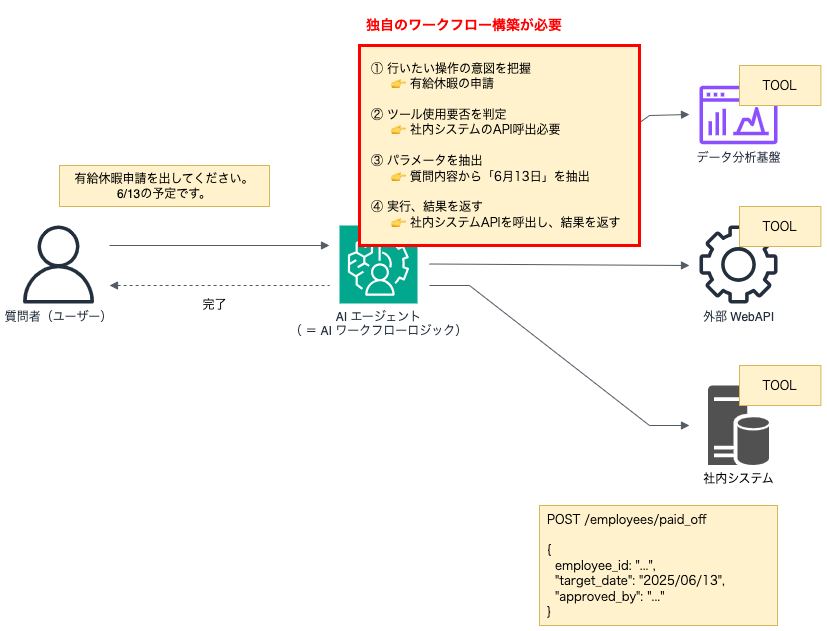
更に細かく細分化すると、目標・依頼事項・質問に対して、適切な回答を生成するために以下のような実装が必要でした。
- AI エージェントに、利用可能なツールの種類を伝えておく
- AI エージェントとツールの繋ぎ込みは、基本的に「スクラッチ実装」する必要がある
- LLM ごとに独自のインタフェースでやり取りしないといけないため、 LangChain ではそのつなぎこみが実装された状態のラッパー関数が提供されている
- LangChain で提供されていないツールは、自分で「スクラッチ実装」する必要がある
- AI エージェントが質問者の課題を解決できるよう「ツールを利用する必要があるか」「どのツールを利用するか」を判断(推論)するプロンプト(ワークフロー)を適用する
- ツールから提供された情報をプロンプトに差し込み、回答を生成する
def process_agent_operation(question, chat_history):
# ① AI エージェントに、利用可能なツールの種類を伝えておく
# 例)https://serpapi.com/
os.environ["SERPAPI_API_KEY"] = "..."
tools = load_tools([“serpapi”], llm=llm)
chat_agent = initialize_agent(
tools,
llm=llm,
agent = "zero-shot-react-description",
verbose=True,
system_message="詳細な情報を日本語で回答してください。",
agent_kwargs={
# ② AI エージェントに、解決に向けて
# 「ツールを利用する必要があるか」、「どのツールを利用するか」を判断させる
'format_instructions': """
To use a tool, please use the following format:
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}].
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)To use a tool, please use the following format:
""",
"input_variables": ["input", "chat_history", "agent_scratchpad"]
}
)
# ③ ツールから提供された情報がプロンプトに差し込まれ、回答を生成する
agent_result = chat_agent.run({
"input": question,
"chat_history": chat_history
})
return agent_result
def main():
question = 'ワンピースの結末について教えてください。わからなければ、検索してください。'
chat_history = []
result = process_agent_operation(question, chat_history)MCPサーバ登場後のAIエージェントの実装
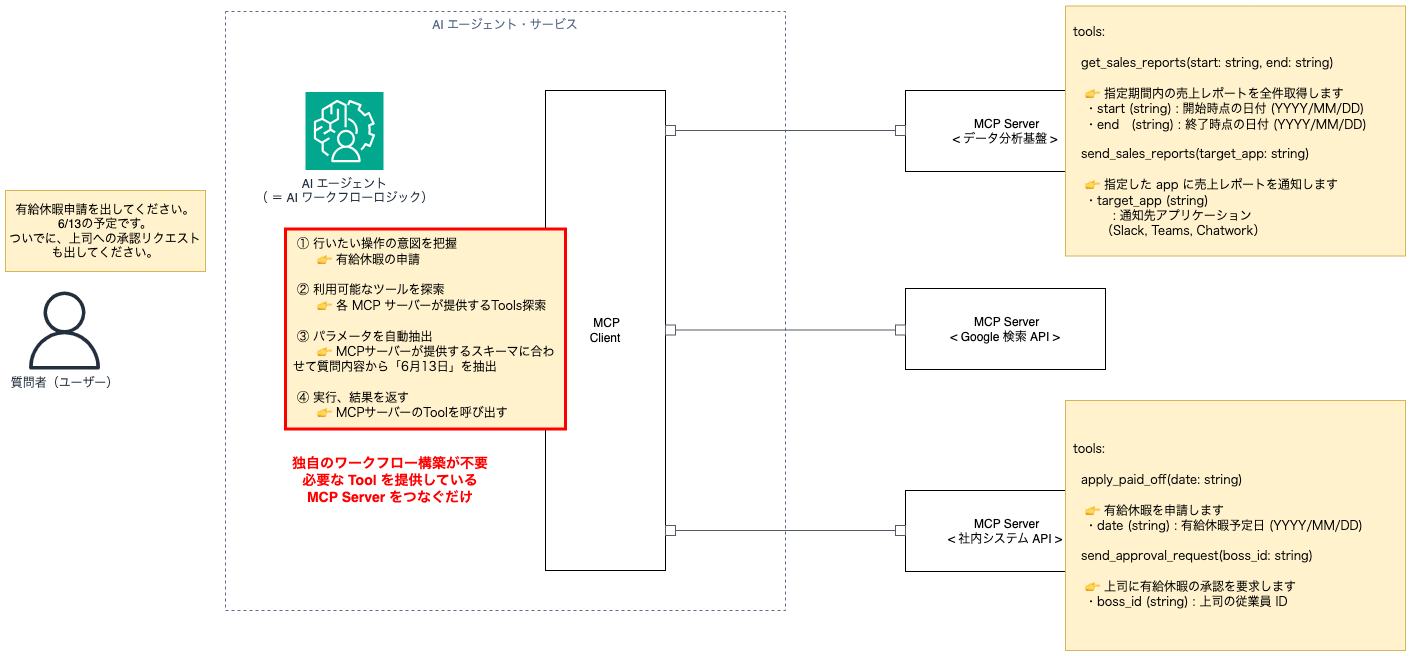
MCPクライアントの実装例が以下にありますが、実装内容が簡略化されて整理されたソースコードになったと感じるのではないでしょうか。要するにこの用に仕様を明確に定義することでみんながAIエージェントを実装しやすくするというのがMCPの正体であると言っても構わないかもしれません。
MCPクライアント実装例
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.prebuilt import create_react_agent
from langchain_aws import ChatBedrock
import asyncio
async def main():
# ① MCP Client が質問を受け付ける
input_text = '2025年7月1日に体調不良のため有給を申請してください(社員ID: E12345)'
llm = ChatBedrock(
region_name=“us-east-1",
model_id="anthropic.claude-3-5-sonnet-20240620-v1:0",
)
# 利用させたい MCP サーバー設定
# https://awslabs.github.io/mcp/servers/aws-documentation-mcp-server/
client = MultiServerMCPClient(
{
# ファイル書き込み機能を提供する MCP Server
"fileio": {
"command": "python",
"args": ["/home/ec2-user/_sandbox/mcp-client-demo/src/fileio_server.py"],
"transport": "stdio", # ローカルMCPサーバーから標準出力(ターミナルで出力される内容)で情報を取得する
},
# 天気予報の情報を提供する MCP Server
"weather": {
"url": "https://weather-api.example.com/mcp/",
"transport": "streamable_http", # リモートMCPサーバーからStreambable HTTP 方式で情報を取得する
},
# 有給申請ツール
"request_paid_leave": {
"url": "http://intra.example.com:8000/mcp/",
"transport": "streamable_http", # リモートMCPサーバーからStreambable HTTP 方式で情報を取得する
}
}
)
# MCPサーバーをツールとして定義
tools = await client.get_tools()
# エージェントの定義(LangGraphでReActエージェントを定義)
# 「推論(Reasoning)」と「行動(Acting)」を交互に繰り返す構造を持つエージェント
agent = create_react_agent(llm, tools)
# 入力プロンプトの定義
agent_response = await agent.ainvoke({
"messages": input_text
})
# 出力結果の表示
pprint.pprint(agent_response, indent=4)
# MCP Client の実行
asyncio.run(main())REST APIが提供される時に、エラーが発生していてもステータスコードが200で返ってきたり、すべてがPOSTで定義されていたら使いにくいと思うでしょう。それと同じような感覚で捉えると分かりやすいかもしれません。サーバーエラーは500系のエラーを返しましょう。データを取得する場合はGETメソッドを使いましょうという仕様が決まっているからこそ、その仕様を前提として使いやすいAPIが提供できるわけです。本質的には同じです。
処理の流れを見てみると以下のとおりです。これを自律的に実行していることがポイントです。
- ユーザーからの質問を受け取る
- その質問に対して、どのMCPサーバー(ツール)を使えばよいかをLLMが判断
- MCPサーバーと通信し、必要なデータを取得 or 操作を実行
- その結果を自然な回答として返す
先程必要だった推論(プロンプト)はMultiServerMCPClientが内包しており実装は不要です。そして共通のインターフェイスが用意されているため、LLMやLangChainに合わせた独自実装も不要になりました。
MCPサーバー実装例
このコードは、FastMCP を使って有給申請処理を行う MCPサーバー(ツール名:request_paid_leave) を定義したものです。@mcp.tool() デコレータで定義された request_paid_leave 関数は、LLM から呼び出される外部ツールとして機能し、社員ID・申請日・理由を受け取って有給申請を記録します。日付の形式チェックも含まれており、フォーマットが正しくない場合はエラーメッセージを返します。ここでは簡易的にメモリ上のリストに申請内容を保存していますが、実運用ではこの部分をデータベース接続に置き換えることで、正式な勤怠管理システムと連携することも可能です。最後に uvicorn を用いてアプリケーションをポート8000で起動し、MCPプロトコルに対応したクライアントからのリクエストを受け付けられる状態にしています。
関数定義の下にこのツールの使い方が記載されていますが、これもコメントのフォーマットがMCPの仕様として定義されています。LLMはMCPクライアントからこのコメントを読み取って、入力内容からどのMCPサーバーを使うべきかを判断します。
from fastmcp import FastMCP
from datetime import datetime
from typing import Literal
# MCP サーバーの初期化("request_paid_leave" = 有給申請用)
mcp = FastMCP("request_paid_leave")
# 仮の有給申請データベース(実際はDB接続などに置き換える)
leave_requests = []
@mcp.tool()
def request_paid_leave(
employee_id: str,
date: str,
reason: Literal["私用", "体調不良", "家族の都合", "旅行", "その他"] = "私用"
) -> str:
"""
指定した社員の有給申請を処理します。
Args:
employee_id: 社員ID(例:E12345)
date: 有給を取得したい日付(例:2025-07-01)
reason: 有給取得の理由(選択肢制)
Returns:
処理結果のメッセージ
"""
try:
# 日付フォーマットチェック
leave_date = datetime.strptime(date, "%Y-%m-%d").date()
except ValueError:
return "日付の形式が正しくありません。例:2025-07-01"
# データ保存(実際にはDB挿入などにする)
leave_requests.append({
"employee_id": employee_id,
"date": leave_date.isoformat(),
"reason": reason
})
return f"{leave_date} の有給申請を受け付けました(理由:{reason})。"
# アプリケーションの起動
if __name__ == "__main__":
import uvicorn
uvicorn.run(mcp.app, host="0.0.0.0", port=8000)LLMからの動作イメージとしては以下のとおりです。
2025年7月1日に体調不良のため有給を申請してください(社員ID: E12345)
↓
LLMがMCPクライアントからツール request_paid_leave を選択
↓
LLMがinputを自然言語から生成し、APIに {“employee_id”: “E12345", “date”: “2025-07-01", “reason”: “体調不良“} を送信
↓
結果を自然言語で「申請を受け付けました」と返答まとめ
このように、MCPという共通仕様に沿ってサーバーを実装することで、従来であれば個別に実装・統合が必要だった外部システムとの接続とワークフローが、まるで「LLMに機能をプラグインするだけ」のような形で実現できます。天気API、ファイル操作、データベース検索、業務ツールとの連携など、目的に応じてツールを追加していけば、AIエージェントはその都度最適な手段を自律的に選び、動作するようになります。MCPサーバーとは、目的に合わせてそのツール群を提供するインターフェースです。
重要なのは、これが「魔法のような新技術」ではなく、あくまでツールとLLMの間のインターフェースを標準化しただけの話だということです。裏側で行われていることの本質は比較的シンプルで、標準化されたプロトコルを通じてコマンドとデータをやり取りしているだけに過ぎません。
LLMを活用したアプリケーションを本格的に構築していきたい開発者にとって、MCPは今後の“分散的なAIシステム開発”を大きく加速する鍵となるはずです。あなたのLLMに「手足」を与える第一歩として、MCP対応のツール実装からぜひ始めてみてはいかがでしょうか。