

まずは、S3 VectorsのインデックスをOpenSearch Serverlessに取り込む手順を行ってみます。この場合前回の手順と異なり検索用エンジンは"engine": "faiss", となります。
GET <index名>/_mapping
{
"<index名>": {
"mappings": {
"properties": {
"key": {
"type": "keyword"
},
"metadata": {
"type": "object"
},
"vector_record": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"engine": "faiss",
"space_type": "cosinesimil",
"name": "hnsw",
"parameters": {
"encoder": {
"name": "sq",
"parameters": {
"type": "fp16",
"clip": true
}
}
}
}
}
}
}
}
}さっそくやってみる
ではさっそくやってみましょう。以下の統合パターン2「S3 ベクトルインデックスから OpenSearch Serverless コレクションへのワンクリックエクスポートにより、高性能なベクトル検索が可能に」を試します。
Amazon S3 Vectors と Amazon OpenSearch Service によるベクトル検索の最適化
S3 Vectors バケットとインデックス の準備
試すためにはまずS3 Vectors のバケットとインデックスが必要となります。適当なものが無い場合、過去のブログ記事の以下を試してみてください。
Amazon S3 Vectors (4) : PDFをデータソースとしたRAGアプリケーションを作る
作成されたVector バケットの中のインデックスのARNをコピーしておきます。
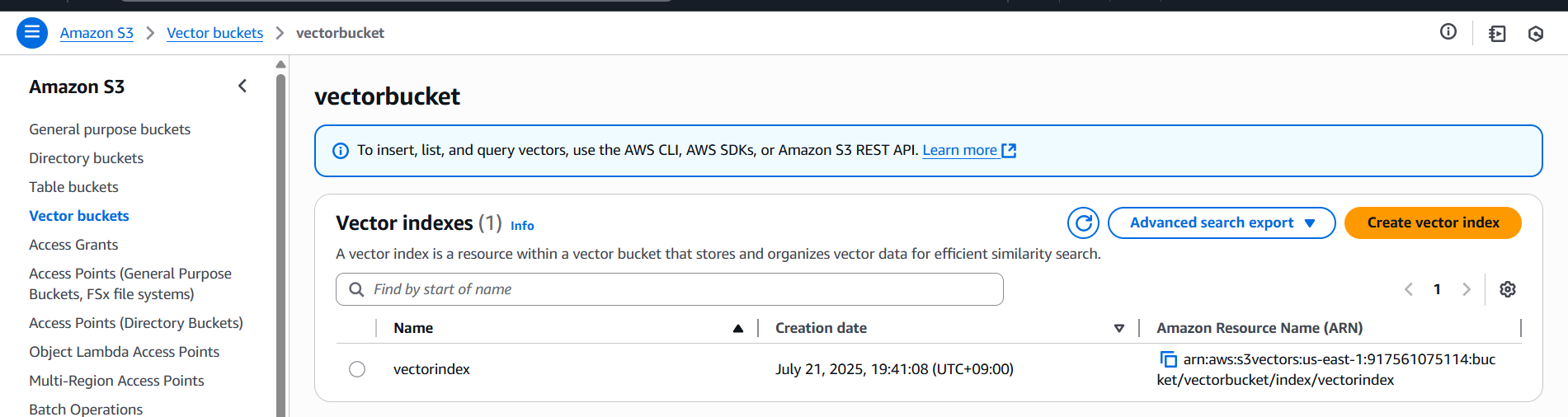
S3 Vectors インデックスのインポートとOpenSearch Serverless クラスターの起動
次にOpenSearch の integration 機能を使ってS3 Vectors のIndexをインポートします。この際、自動でOpenSearch Serverless クラスターが起動します。
コンソール左ペインから Integrations を選択します。
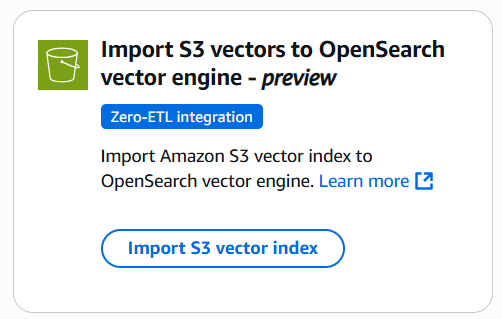
Import S3 Vector Index をクリックします。
先ほどコピーしたS3 Vectors バケットの中にあるインデックスのARNを入力します。
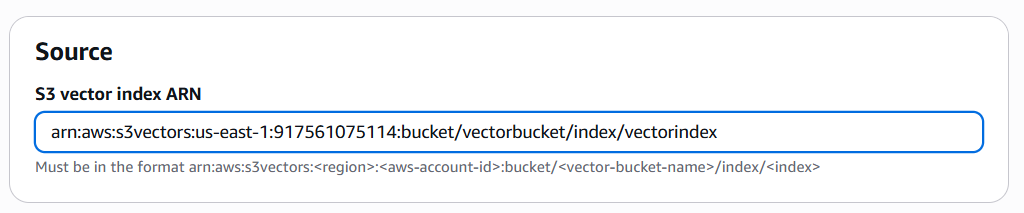
Importをクリックします。
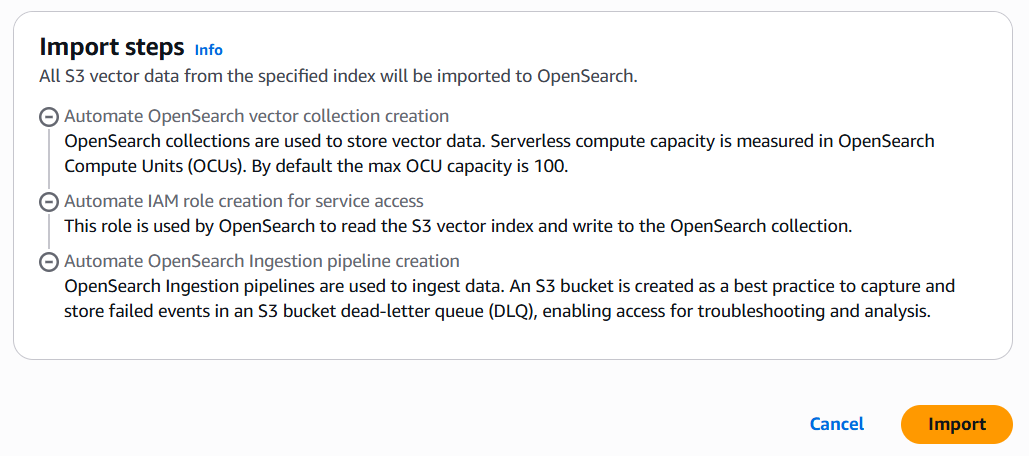
OpenSearch Serverless クラスターが起動されますので少し時間がかかりますのでまちます。
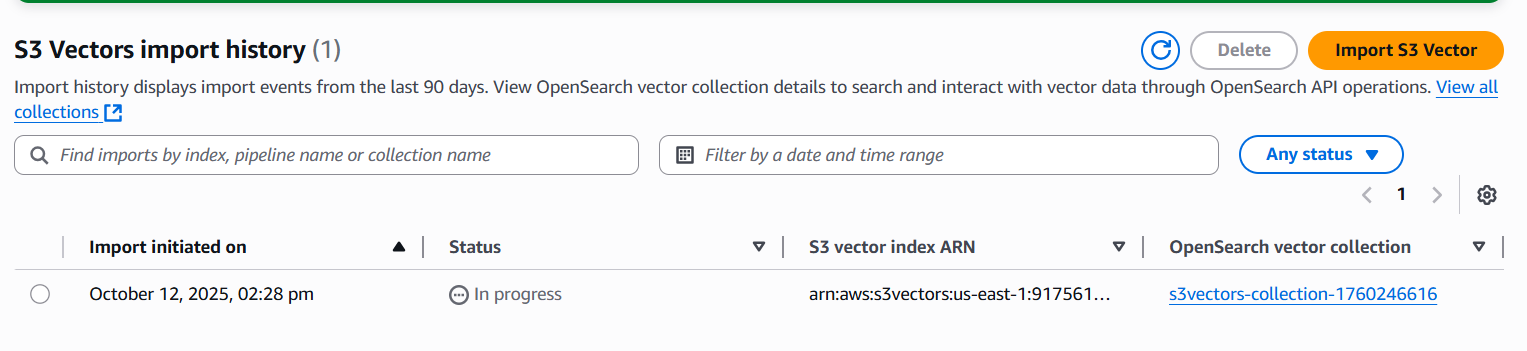
クラスターが起動された後データインポートが開始されますのでさらに待ちます。ステータスは Import History から確認できます。
ベクトル検索のテスト
インポートが完了したらServerlessクラスターのダッシュボードにアクセスします。
まず以下を実行します。
GET _search
{
"query": {
"match_all": {}
}
}{
"took": 81,
"timed_out": false,
"_shards": {
"total": 0,
"successful": 0,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "vectorindex-1760246616",
"_id": "1%3A0%3ApEzo1pkBeo7hq2ZBm7US",
"_score": 1,
"_source": {
"vector_record": [
-0.005708329,
0.044577774,
-0.055490192,vectorindex-1760246616 というインデックスが出来ています。
このベクトルストアは1024次元ベクトルが格納されています。このためベクトル類似度による検索も1024次元ベクトルを使う必要があるため以下のクエリを実行します。
GET vectorindex-1760246616/_search
{
"size": 6,
"query": {
"knn": {
"vector_record": {
"vector": [
0.954976,
0.348797,
0.527794,
0.85656,
0.380076,
0.035756,
0.744037,
0.218038,
0.970145,
0.463926,
0.945905,
0.05344,
0.544454,
0.530458,
0.485897,
0.756312,
0.768365,
0.142837,
0.864055,
0.046203,
....途中省略(1024次元分のベクトルデータを指定します)
0.453234
],
"k": 5
}
}
}
}以下の様に類似度の高いベクトルデータが検索結果として出力されました。
{
"took": 62,
"timed_out": false,
"_shards": {
"total": 0,
"successful": 0,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.51760745,
"hits": [
{
"_index": "vectorindex-1760246616",
"_id": "1%3A0%3ApEzo1pkBeo7hq2ZBm7US",
"_score": 0.51760745,
"_source": {
"vector_record": [
-0.005708329,
0.044577774,
-0.055490192,
0.061017435,また、作成されたベクトルインデックスの設定は以下のコマンドで確認ができます。
GET vectorindex-1760246616/_settings
GET vectorindex-1760246616/_mapping
---
{
"vectorindex-1760243727": {
"mappings": {
"properties": {
"vector_record": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "nmslib"
}
}
}
}
}
}まとめ
非常に簡単なプロセスでAmazon S3 VectorsからOpenSearch Serverlessへのベクトルデータの移行が完了しました。ユースケースとして、スモールスタートで最初はS3 Vectorsを使ってRAGなどを構築、サービスが成長すればOpenSearch Serverlessの高速なクエリパフォーマンスや自動スケーリングなどの特性を利用してよりよいサービスを顧客に提供するなどが可能になるでしょう。