

過去、Amazon S3 Vectors (4) : PDFをデータソースとしたRAGアプリケーションを作るでAmazon S3 Vectors を用いたRAGを構築しました。
S3 Vectorsはまだβ提供のサービスであり東京リージョンにはありません。今回はAmazon S3 Vectors と Amazon OpenSearch Service によるベクトル検索の最適化のブログに2つの統合パターンが手順付きで解説されているのでやってみます。
さっそくやってみる
この記事ではまず統合パターン1である「S3 Vectors を使用した OpenSearch Service マネージドクラスター」を試して行きます。
OpenSearch クラスターの起動
S3 Vectors 統合を試すためにはOpenSearch Optimized(OR1)というOpenSearch Optimized インスタンスを起動する必要があります。
Standard Createを指定して細かいパラメータ設定を行えるようにします。
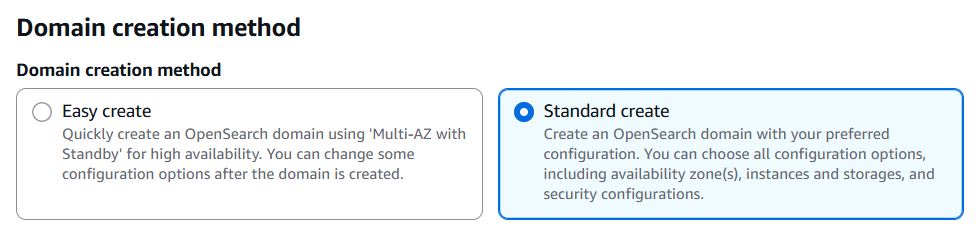
ブログでは2.19を用いていますが、最新版の3.1でもこの機能は利用できるため最新版を起動します。
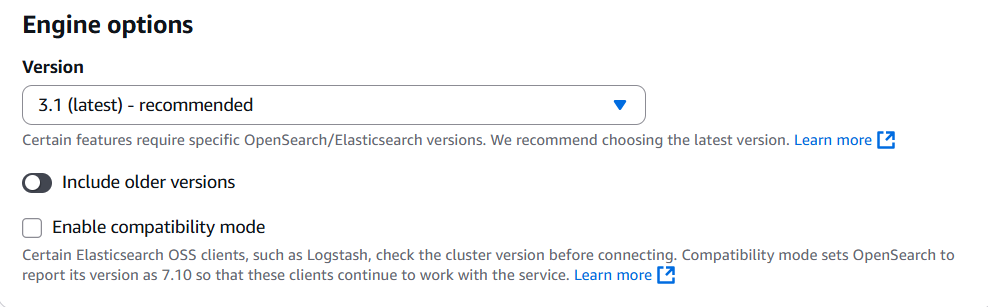
Instance FamilyでOpenSearch Optimizedを指定します。
テスト用ですので一番小さいor1.mediumを指定します。
Advanced featuresでEnable S3 Vectors as an engine option - previewを有効化します。
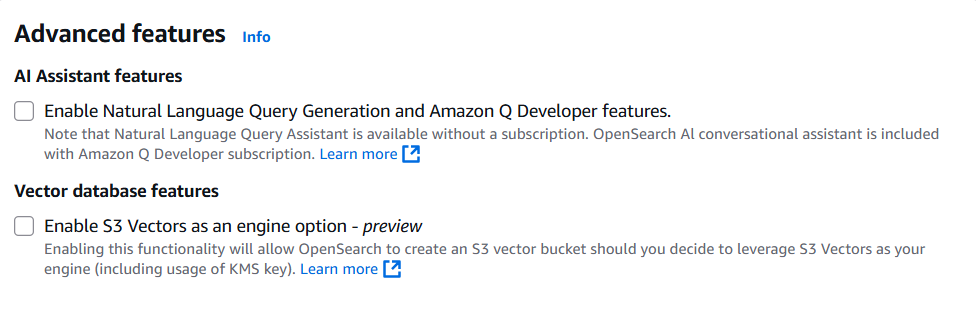
起動するまで10分程度かかりますので待ちます。
DevToolでベクトルストアの設定
起動したらダッシュボードにアクセスを行い、DevToolsを起動します。
以下のコマンドを実行します。
PUT my-first-s3vector-index
{
"settings": {
"index": {
"knn": true
}
},
"mappings": {
"properties": {
"my_vector1": {
"type": "knn_vector",
"dimension": 2,
"space_type": "l2",
"method": {
"engine": "s3vector"
}
},
"price": {
"type": "float"
}
}
}
}"engine": "s3vector" でエンジンにS3 Vectorsを指定しています。
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "my-first-s3vector-index"
}データの書きこみとテスト
ではまずデータを書き込んでみます。以下を実行します。
POST _bulk
{ "index": { "_index": "my-first-s3vector-index", "_id": "1" } }
{ "my_vector1": [2.5, 3.5], "price": 7.1 }
{ "index": { "_index": "my-first-s3vector-index", "_id": "3" } }
{ "my_vector1": [3.5, 4.5], "price": 12.9 }
{ "index": { "_index": "my-first-s3vector-index", "_id": "4" } }
{ "my_vector1": [5.5, 6.5], "price": 1.2 }
{ "index": { "_index": "my-first-s3vector-index", "_id": "5" } }
{ "my_vector1": [4.5, 5.5], "price": 3.7 }
{ "index": { "_index": "my-first-s3vector-index", "_id": "6" } }
{ "my_vector1": [1.5, 2.5], "price": 12.2 }このサンプルではシンプルに2次元ベクトルを使用していますが、実際のワークロードで生成AIの埋め込みモデルを使った場合、数百次元のベクトルが必要となるでしょう。
では、検索を実行します。
GET my-first-s3vector-index/_search
{
"size": 2,
"query": {
"knn": {
"my_vector1": {
"vector": [2.5, 3.5],
"k": 2
}
}
}
}このリクエストでは my_vector1 に対して [2.5, 3.5] に最も近いベクトルを k=2 件返すよう指定しています。
{
"took": 455,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "my-first-s3vector-index",
"_id": "1",
"_score": 1,
"_source": {
"my_vector1": [
2.5,
3.5
],
"price": 7.1
}
},
{
"_index": "my-first-s3vector-index",
"_id": "3",
"_score": 0.33333334,
"_source": {
"my_vector1": [
3.5,
4.5
],
"price": 12.9
}
}
]
}1件目は同じ値が格納されていたため完全一致(score:1)で結果が戻ってきています。
2件目は最も近しい値が戻っています。この時のベクトル比較アルゴリズムはインデックスを作成した以下で指定されます。今回はl2と値を指定して、ユークリッド距離を使用してベクトル検索を行いました。
"space_type": "l2",この手順で作成された S3 Vectors バケットはS3のマネージメントコンソールからは確認ができるが、独立した操作は行えません。OpenSearch クラスター上でS3 Vectors バケットのARNも確認ができないようになっており、OpenSearchからに組み込まれたストレージとして隠蔽されているような設計となっているようです。
まとめ
この用にS3 VectorはS3バケットからは隠蔽されているような形で存在し、OpenSearchのストレージの一部かのように動作します。今回は大量データでテストをしていないため、レイテンシーがどの様に犠牲になるかまでは試していません。しかし、OpenSearchが提供しているセマンティック検索やニューラル検索、ハイブリッド検索などの様々なベクトル検索の機能はそのまま使えそうです。是非、コスト最適化のための選択肢として覚えておきたい統合機能ですね!