

昨年は ChatGPT が広く使われるようになり、OpenAI の API を使って生成 AI を活用したオリジナルサービスやアプリケーションが開発できるようになりました。AWS でも生成 AI サービスとして Amazon Bedrock が昨年リリースされており、生成 AI を利用したシステム構成がどのようなものか、気になっている方も多いのではないでしょうか。
ここで、最近は汎用的な内容だけでなく、あらかじめ回答してほしいコンテキストを用意し、生成 AI に対してその内容に基づいての回答を求めることが可能になっています。
この記事では、生成 AI の中でもテキストの自然言語処理を担う LLM(「ChatGPT」のような大規模言語モデル)を活用した仕組みとして、Retrieval-augmented Generation(RAG、検索により強化した文章生成)を、「AWS フルサーバーレス」及びサーバーレスに特化したサービス「Momento」を使って実現する構成と、LangChain というライブラリを利用して実装する具体的な方法についてご紹介します。
RAG の基本構成
RAG とは LLM が回答を生成する際、LLMのモデルには含まれない外部のデータを参照・検索し、その結果をもとに回答を生成する仕組みです。これによって独自のドキュメントを検索して回答を生成したり、新たな知識・情報の追加が可能になるため、生成 AI を利用したサービスやソリューションの基本構成として定着しつつあります。この RAG 構成において最もよく使われるライブラリが LangChain です。
※記事のサンプルコード作成時のバージョン情報
langchain-community==0.0.13
langchain-core==0.1.11LangChain を使った RAG 構成では、大きく以下のステップで処理が行われます。
- ソースデータを読み込み、ベクトルデータへ変換(「Embedding」と言います)
- 変換したデータをVector store と言われる DB に保存
- 質問(プロンプト)と関連する情報を Vector store から検索
- 検索結果の内容に基づいて回答を生成
LangChain はこのような一連の流れが高いレベルで抽象化されており、各ステップの処理を事細かく意識して実装する必要はありませんが、このようなステップを理解しておくことはシステム構成の設計において大きく役立ちます。
固定費ゼロ、AWS フルサーバーレスでRAGを構築したい
生成 AI を活用した実証実験などが盛んに行われてきている中、気になるポイントがあります。一般的に AI 関連サービスの料金は高額になる傾向があり、特に RAG 構成においては Vector store の扱いに悩まされる方も多いのではないでしょうか。
RAG のシステム構成では大きく以下のコンポーネントに分けられます。
分類 | 詳細 |
|---|---|
| Bedrock + Amazon Titan や、OpenAI + GPT 3.5 など |
| ソースとなるデータを読み込んだり、質問と回答をもらうコンピューティング処理 |
| ベクトル化したデータを保存・検索 |
| チャットの会話履歴などを保存する一般的なDBなど |
「1 . LLM 」そのものはさておき、「2. アプリケーションロジック」は AWS Lambda で対応させることが可能です。また 「4.その他」 に関してもユースケースによりますが DynamoDB を活用することが可能ですし、後述する Momento というサービスの Cache を利用することも可能です。
AI を活用するシステム全般における費用傾向を考えると、可能な限り固定費を抑えたくなるものですが、多くの RAG 構成では一つ問題になるのがこの「3. Vector store」です。AWS のソリューションとしては OpenSearch があり、OSS では Chroma DB などがあります。また SaaS として提供される Pinecone, Momento といったサービスがありますが、この記事では Momento の Vector Index を利用することにします。
※ Knowledge base for Amazon Bedrock を活用した構成につき、Pinecone を活用した構成をこの記事の続編で投稿しました。
以下、Vector store を選定する際の参考になれば幸いです。他にもたくさんのソリューションがありますが、AWS 関連でよく候補に上がるものとしてピックアップしてみました。
項目 | 内容 |
|---|---|
OpenSearch |
|
Chroma DB |
|
Pinecone |
|
Momento Ventor Index |
|
全体 Overview
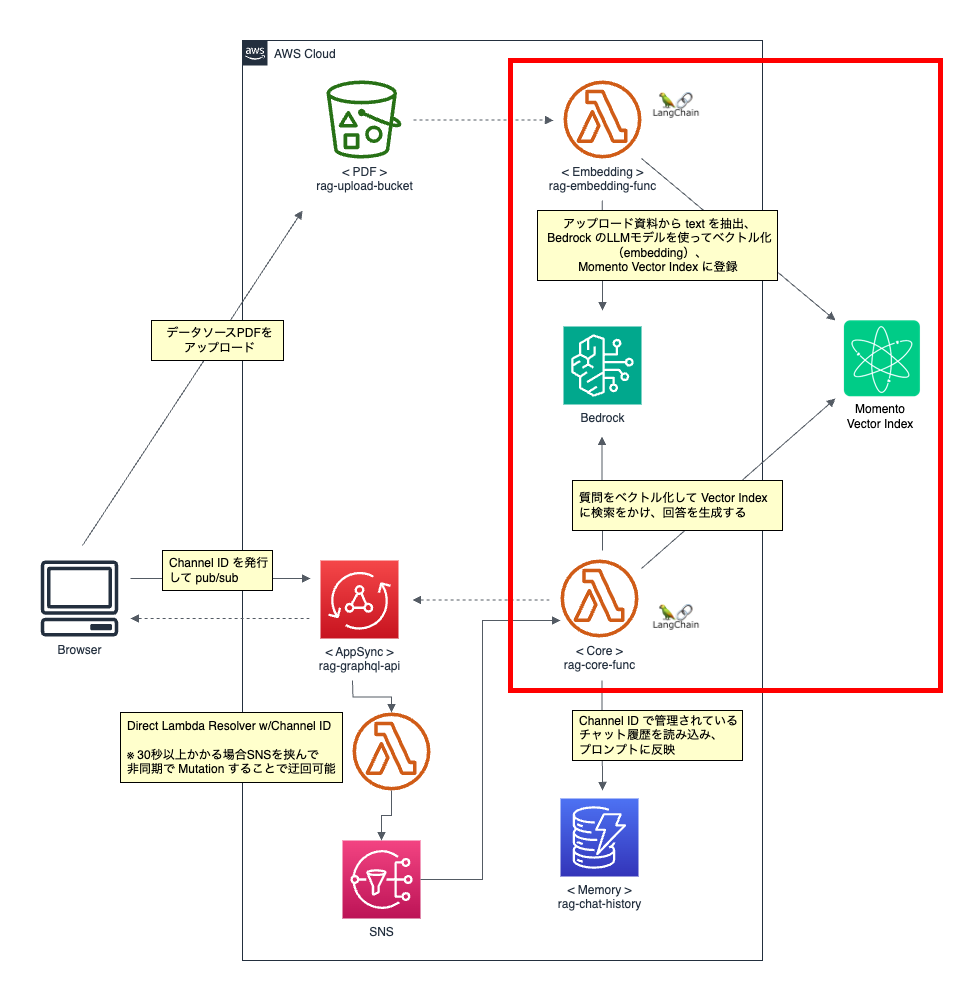
リアルタイムなチャットアプリを想定した構成になっていますが、本記事で説明する範囲は赤枠です。また、Lambda のロジックには LangChain が含まれおり、ランタイム言語は Python を利用します。
構築を行う前の事前準備
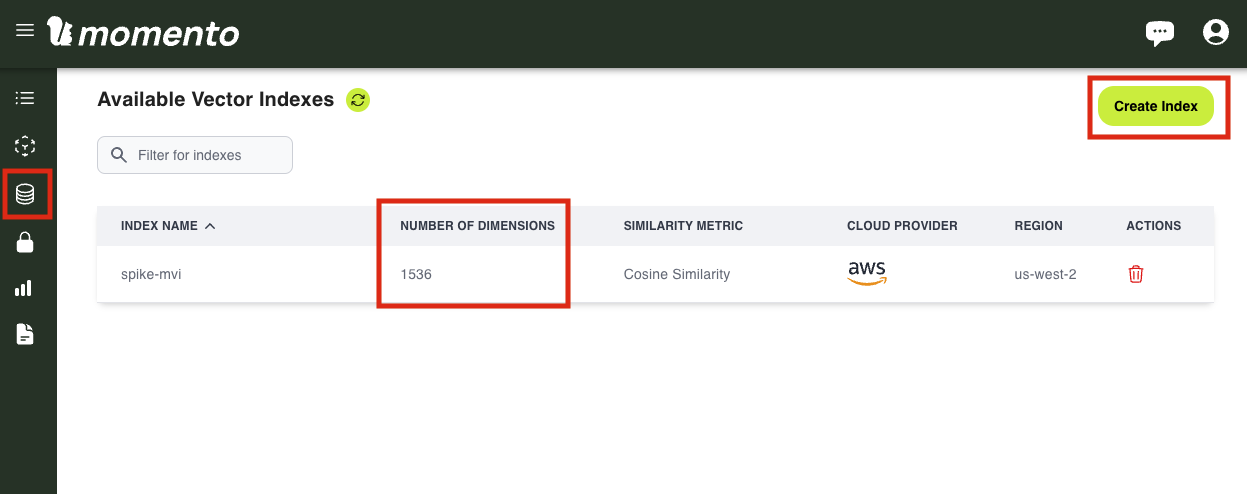
まずは、Momento Vector Index を利用するため、Momento に登録して index 作成を行います。
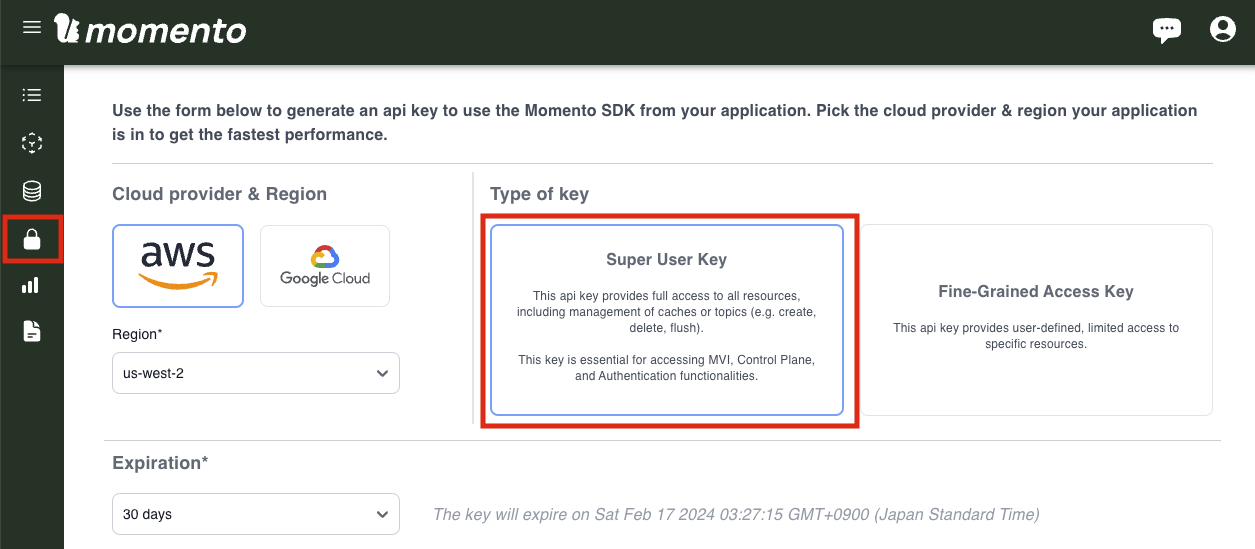
Momento Vector Index を利用するためにはこちらの Super User Key が必要になります。生成して環境変数に登録しておきます。
次に、Amazon Bedrock のコンソールに移動します。検証時はBedrock 含め新サービスのアップデートが早い us-east-1 リージョンを選択するのがおすすめです。初回利用の場合は左側メニューの Model access から利用するモデルの利用申請を出して解除する必要があります。基本的にはどれも従量課金制なので、他にも使いたいものは解除しておいても特に問題ありません。
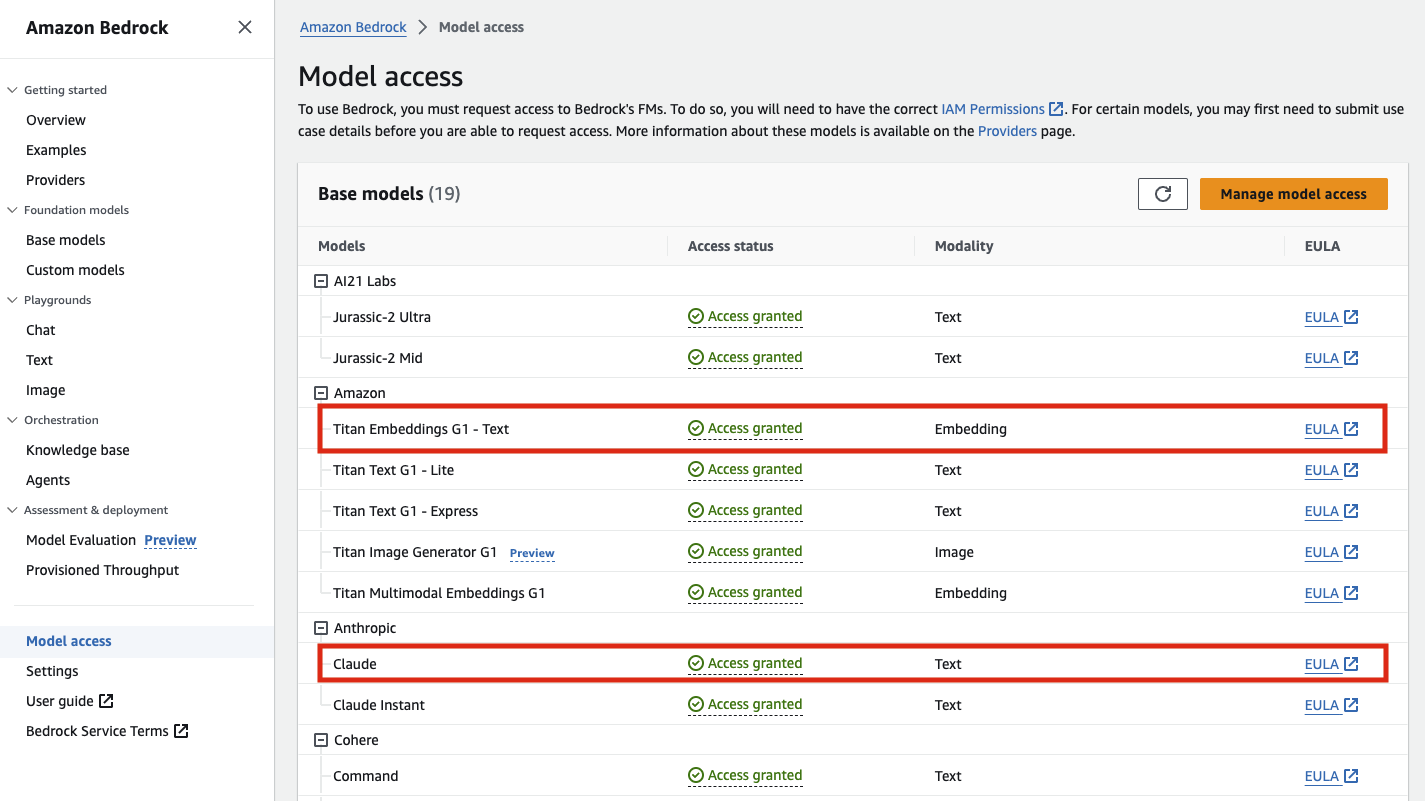
今回は、「Amazon - Titan Embeddings G1 - Text」と「Anthropic - Claude」を利用します。テキストの Embedding には Amazon Titan を利用するしかなく、テキストの生成にはトークン数の上限が高く(~100k)、日本語処理に有利な Claude を利用します。リクエストを出してしばらく待つと、数分〜数十分で利用可能になります。AWS Marketplace から Subscription 登録が行われた旨のメール通知がアカウント管理者に飛びますので、ご承知おきください。
データを読み込み Embedding する処理の詳細
基本構成の以下ステップの対応です。
- ソースデータを読み込み、ベクトルデータへ変換(「Embedding」と言います)
- 変換したデータをVector store と言われる DB に保存
実際に embedding を行うサンプルです。サンプルではあるtextファイルを読み込むことにしていますが、他にも CSV, HTML, JSON, Markdown, PDF, ディレクトリ指定に対応可能です。
import boto3
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import BedrockEmbeddings
from langchain_community.vectorstores import MomentoVectorIndex
from momento import (
CredentialProvider,
PreviewVectorIndexClient,
VectorIndexConfigurations,
)
API_KEY_ENV_VAR_NAME = 'MOMENTO_API_KEY'
MVI_INDEX_NAME = 'spike-mvi'
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
def load_text_data(path: str) -> None:
# 指定したパスのファイルを読み込みます
loader = TextLoader(path)
data = loader.load()
# 読み込んたファイルのテキストを分割(chunk)し、最適化を行います
# chunk ができていないと、検索時の性能やトークン消費量に影響します
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
# Embedding: ベクトルデータへの変換処理を行ってくれる LLM を指定します
# ここでは Bedrock を利用します
# 同様に OpenAI を利用することも可能です
embeddings = BedrockEmbeddings(
client=bedrock_runtime,
model_id="amazon.titan-embed-text-v1",
region_name="us-east-1"
)
# Embedding を行い、Vector Store へ登録します
MomentoVectorIndex.from_documents(
all_splits,
embedding=embeddings,
client=PreviewVectorIndexClient(
configuration=VectorIndexConfigurations.Default.latest(),
credential_provider=CredentialProvider.from_environment_variable(
API_KEY_ENV_VAR_NAME
),
),
index_name=MVI_INDEX_NAME,
)テキストファイル以外の読み込み方法については、こちらの LangChain 公式ドキュメントをご参考ください。特に PDF がよく使われます。
質問(プロンプト)から Vector Store を検索、回答を生成する
基本構成の以下ステップの対応です。
- 質問(プロンプト)と関連する情報を Vector store から検索
- 検索結果の内容に基づいて回答を生成
まず「プロンプト」を定義します。別途プロンプトを作成しなくても LangChain の内部で予め決まっているプロンプトが使われますが、回答の精度をあげたり、カスタマイズできるようにするには、例えば以下のようにプロンプトを用意しておく必要があります。
# prompt.py
prompt_template_qa = """
日本語で、回答に関連する内容を詳細に回答してください。
{context}
質問: {question}
回答:"""{context} および {question} については、プロンプトテンプレートを作成するときに指定が必要になるテンプレート変数です。今回の実装では質問内容が {question} に反映される形になります。
本処理に関しては以下のようになります。
import boto3
from langchain_community.llms import Bedrock
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_community.vectorstores import MomentoVectorIndex
from momento import (
CredentialProvider,
PreviewVectorIndexClient,
VectorIndexConfigurations,
)
from prompts import prompt_template_qa
from langchain_community.embeddings import BedrockEmbeddings
API_KEY_ENV_VAR_NAME = 'MOMENTO_API_KEY'
MVI_INDEX_NAME = 'spike-mvi'
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
def process_qa(question):
# Bedrock の llm を指定
llm = Bedrock(
client=boto3.client("bedrock-runtime", region_name="us-east-1"),
model_id="anthropic.claude-v2",
model_kwargs={"temperature": 0.0, "max_tokens_to_sample": 500},
)
# 質問を含めベクトルを扱う Bedrock の Embedding を指定
embeddings = BedrockEmbeddings(
client=bedrock_runtime,
model_id="amazon.titan-embed-text-v1",
region_name="us-east-1"
)
# 検索を行う Vector Store を
vectorstore = MomentoVectorIndex(
embedding=embeddings,
client=PreviewVectorIndexClient(
configuration=VectorIndexConfigurations.Default.latest(),
credential_provider=CredentialProvider.from_environment_variable(
API_KEY_ENV_VAR_NAME
),
),
index_name=MVI_INDEX_NAME,
)
# retriever: 外部データを用いて回答を生成すること
retriever = vectorstore.as_retriever()
# 先ほど作成したプロンプトのテンプレートを作成します。
# {question} に質問内容が反映されます。
# 会話履歴などを反映させる場合は、{chat_history}など任意の変数を指定することも可能です。
prompt_qa = PromptTemplate(
template=prompt_template_qa_ja,
input_variables=["context", "question"]
)
# retriever を利用して回答を生成し、
# その際に先ほど作成したプロンプトを反映した上で処理を行ってくれる機能です。
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff',
retriever=retriever,
chain_type_kwargs={"prompt": prompt_qa}
)
# 質問を投げて回答を表示します
result = qa.invoke(question)
print(result['result'])
return result実行結果
例として、以下のようなサンプルテキストで Embedding を行ったとします。
渋谷区の燃やすごみになるもの:
生ごみ
食用油
紙くず、古紙回収に出せない紙類
植木の葉・枝
衣類、紙おむつ
プラスチック製品
汚れている容器包装プラスチック
ゴム・皮革製品
分別回収に出せないペットボトル
渋谷区での燃やすゴミ排出時のお願い:
生ごみは、水きりをして出してください。
食用油は、紙や布にしみ込ませるか、凝固剤で固めて出してください。
植木の葉・枝は、50cm程度の長さにしてから、2~3束ずつ出してください。
紙おむつは、汚物を取り除いてから出してください。
生理用品、混紡衣類、化学雑巾、たばこの吸殻などは、複合素材でできていますが、可燃ごみになります。まず Embedding のサンプルコードで作成した load_text_data を実行し、その後、 process_qa にて以下のように質問してみます。
load_text_data('sample_text.txt')
process_qa('渋谷区では、燃やすゴミに生ゴミは含まれますか?')
はい、渋谷区の燃やすゴミには生ゴミが含まれます。
渋谷区の燃やすゴミになるもののリストに、「生ごみ」と明記されています。
また、渋谷区での燃やすゴミ排出時のお願いとして、「生ごみは、水きりをして出してください」と記載があります。
したがって、渋谷区では生ゴミは燃やすゴミの対象となり、水きりをしてから出すようお願いしていることがわかります。事前に登録したテキストの内容に沿って回答が返ってきました。少し文章が長いので、結論だけ短く教えてもらうように、プロンプトを修正して回答のカスタマイズを行ってみます。
# prompt.py
# 「詳細に」→「結論だけ簡潔に」
prompt_template_qa = """
日本語で、回答に関連する内容を結論だけ短く回答してください。
{context}
質問: {question}
回答:"""もう一度、同じ質問を投げてみると、回答がかなり短くなっていることが分かります。
load_text_data('sample_text.txt')
process_qa('渋谷区では、燃やすゴミに生ゴミは含まれますか?')
はい、渋谷区の燃やすゴミには生ゴミが含まれます。終わりに
いかがだったでしょうか。LangChain や 生成 AI の脈略での用語や実装方法に戸惑うこともあると思いますが、抽象化されている機能を理解しておくことで、使いこなせるようになることもあるかと思います。OpenAI を使った同様の構成例は多々ありますが、AWSフルサーバレスを基本として固定費をゼロに抑え、さらに、Vector Store に関しては Momento を利用するのが実用的でおすすめの構成案になります。
LangChain 及び 生成 AI という分野は日々新しい機能がリリースされ、変更や改善が盛んに行われています。会話履歴に基づく回答や Knowledge base といった新機能の続編記事もリリースされますので、キャッチアップしていただく上でお役に立てると幸いです。
本記事におけるご不明点などは弊社サイトからお気軽にお問い合わせください。