

01) IAM Policyを作成してインスタンスロールにアタッチする
IAM Policyの作成
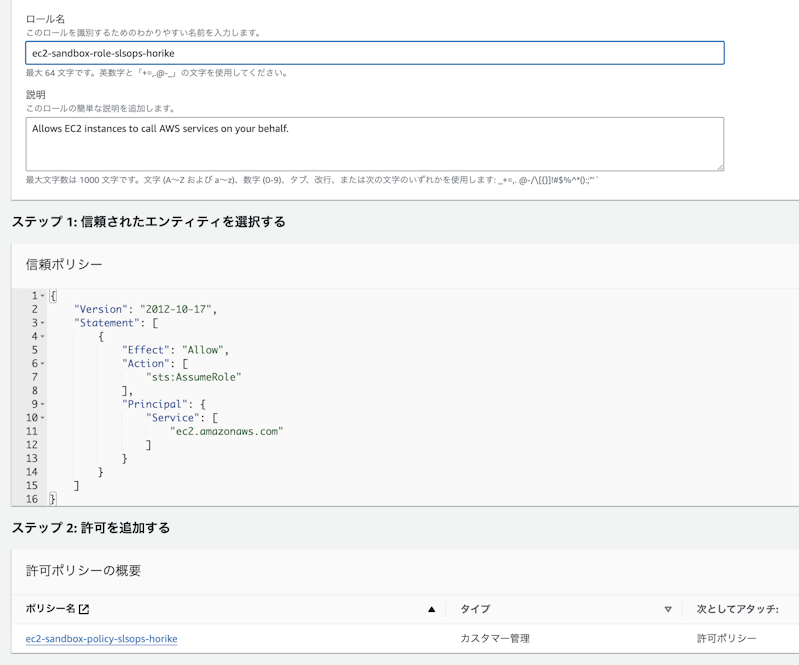
まずはインラインポリシーを作成します。あなたの開発環境から接続するAWSサービスのアクションを許可していきましょう。例えばAmazon SageMakerでAIモデルのトレーニングを行い、Amazon S3にトレーニング済みのAIモデルを格納するようなプロジェクトの場合だと以下のようなポリシーが必要になります。ポリシー名はec2-sandbox-polocy-{org_name}-{user_name} など分かりやすい命名規則にしましょう
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::your-bucket-name/*"
},
{
"Effect": "Allow",
"Action": [
"sagemaker:*"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}IAM Roleの作成
sts:AssumeRole ポリシーを含めて IAM Role を作成し、上記で作成したIAM Policyをアタッチします。ロール名はここではec2-sandbox-role-{org_name}-{user_name} とします。
02) インスタンス作成
Amazon EC2 インスタンスを作成していきます。画像処理やAI関連では x86 プロセッサーの選択をおすすめします。現段階ではGravitonの場合、未サポートや動作が不安定なAI関連のライブラリが結構あります
インスタンス名・タイプ・サイズ
- x86 プロセッサーの場合
- インスタンス名
ec2-sandbox-{org_name}-{user_name}-x86_64
- 推奨インスタンスタイプ・サイズ
t3.large、t3.xlarge
- 用途
- 画像処理・AI 関連・「複雑なデータ分析処理」などではこちらを選択
- インスタンス名
- Graviton プロセッサーの場合
- インスタンス名
ec2-sandbox-{org_name}-{user_name}-aarch64
- 推奨インスタンスサイズ・タイプ
t4g.large、t4g.xlarge
- 用途
- WebAPI、バッチ処理、ETLなど「大量処理」が必要な場合は場合はこちらを選択
- インスタンス名
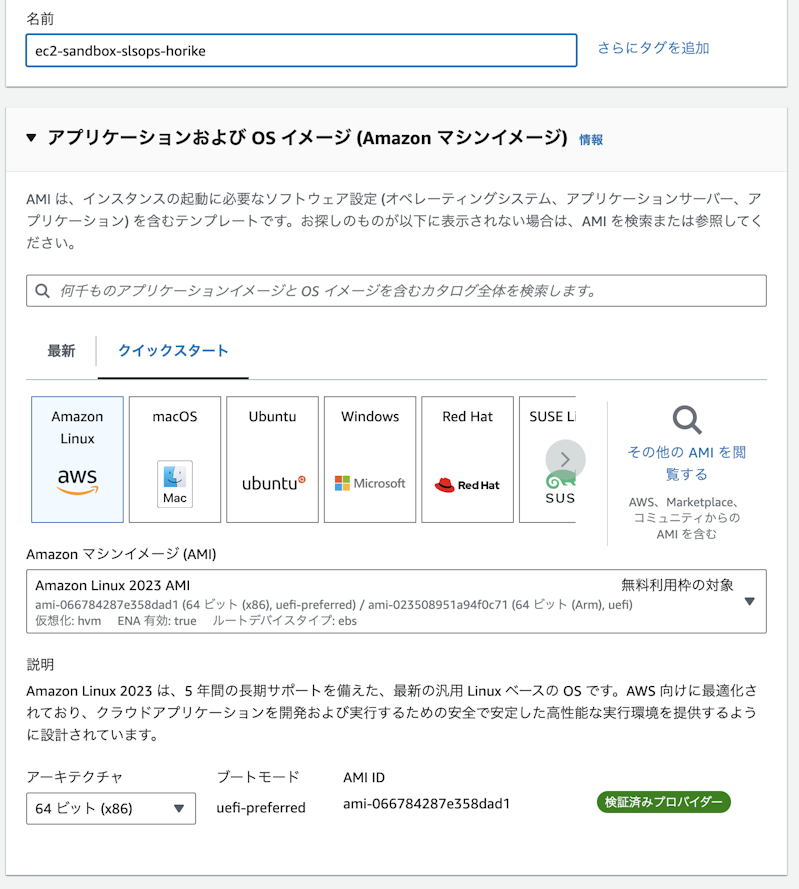
インスタンスロールの指定
一番最初に作成したインスタンスロールを指定します。
ec2-sandbox-role-{org_name}-{user_name}
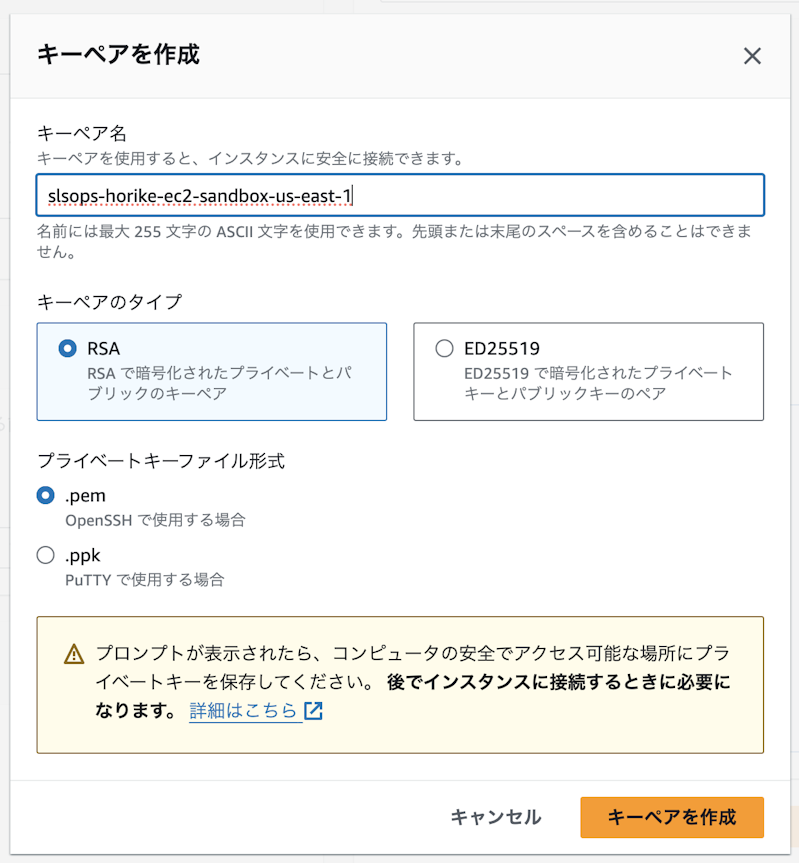
キーペア名
以下のようなフォーマットにしてファイル名も同様にしておくのがおすすめです。リージョン名を含めておくと便利です。
{org_name}-{user_name}-ec2-sandbox-{region_name}
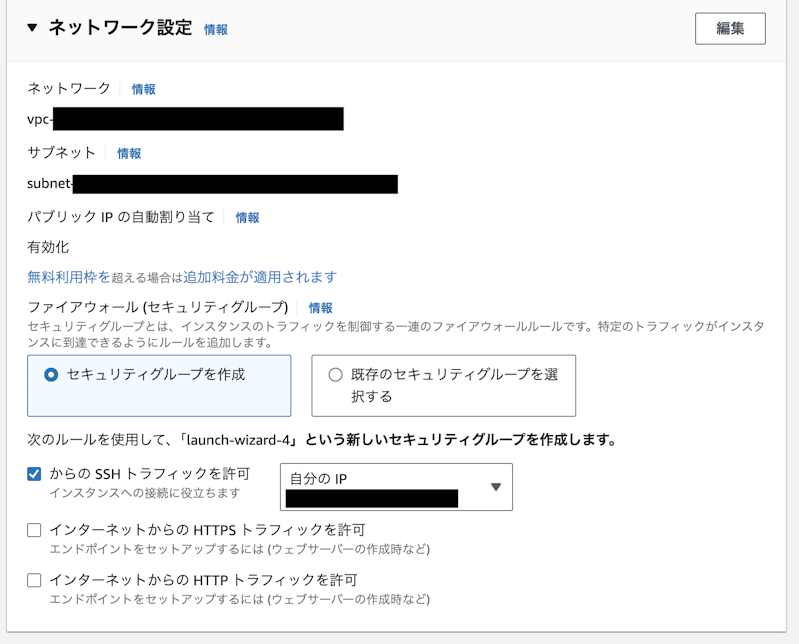
ネットワーク設定
今回はパブリックサブネットに配置して利用するので、Auto-assign public IP を Enable にします。
※ System Manager - Session Manager を利用して、プライベートサブネットで利用することも可能です。
セキュリティグループ
22番ポートのみ、Inbound に My IP または社内 IP レンジを指定します。
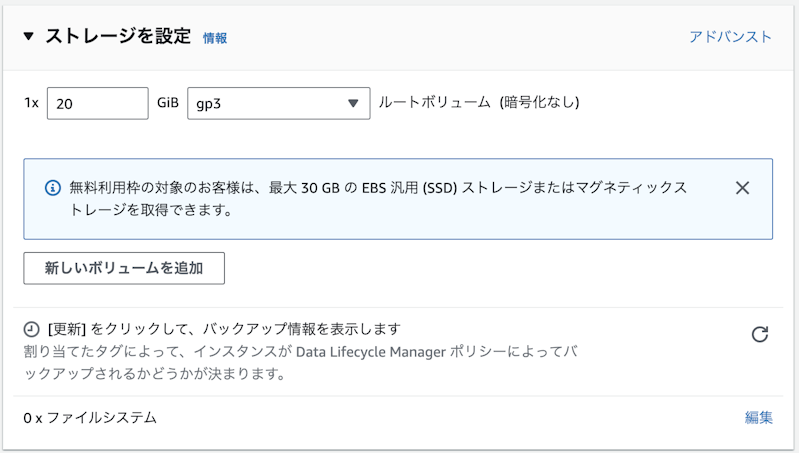
ストレージ
20GB以上、Docker を利用する場合は 50GB 以上をお勧めします。
03) SSH 接続
インスタンス作成後、接続元(ローカルPC)の ~/.ssh/config に、以下のように追記します。
Host slsops.lopburny.ec2-sandbox.x86_64
HostName {EC2_PUBLIC_IP}
IdentityFile ~/.ssh/{PRIVATE_KEY_FILE_NAME}.pem
User ec2-user
秘密鍵ファイルを ~/.ssh/ に配置、権限設定をします。
# ~/.ssh/
chmod 600 {PRIVATE_KEY_FILE_NAME}.pem
接続コマンド例
ssh ec2-user@{PUBLIC_IP} -i ~/.ssh/{PRIVATE_KEY_FILE_NAME}.pem
04) Amazon Linux 2023 環境設定
SSH でインスタンスに入って、以下順番に対応していきます。
依存ライブラリのインストール
sudo dnf -y install \
git gcc zlib-devel bzip2-devel readline-devel \
sqlite sqlite-devel \
openssl-devel tk-devel libffi-devel xz-devel
Python (pyenv) セットアップ
pyenv のインストールします。pyenvは、複数のPythonバージョンを簡単に管理するためのツールです。これを使うと、システムにインストールされたPythonバージョンに依存することなく、プロジェクトごとに異なるPythonバージョンを利用することができます。pyenvのようなランタイムのバージョンを切り替えるツールを入れておくと以下のような観点で便利です。
- Lambda のランタイムとちょうど合わせてテストしたい時に便利
- python だと特に3.8 でしか動かないパッケージもあれば、3.11 で開発するプロジェクトもあるので、切り替えができると便利。Node も Lambda では v20 までだけど、フロントエンドだと v22 使いたくなったりする。もしくは古いプロジェクトだといまだに v16 でしか動かなくてメンテ必要な場合もある(v16 -> v18 で互換性問題が一番多い)
- ポータブルでインストーラーなど不要で、簡単に削除したりインストールしたりできて環境が汚れにくい
# git clone で入れるのが最も手軽でおすすめです。
git clone <https://github.com/pyenv/pyenv.git> ~/.pyenv
pyenv にパスを通します。
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
echo 'command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init -)"' >> ~/.bashrc
source ~/.bashrc
最後にPythonをインストールして、pyenvに登録を行います。
# 数分ほどかかります。
pyenv install 3.11
pyenv global 3.11.9
python --version
pip --version
Node.js (nodenv) セットアップ
Pythonプロジェクトとはいえ、Node.jsを今後ツールとして使うケースも出てくる可能性があるので、Node.jsもインストールしていきます。まずはnodenv をインストールします。これはpyenvのNode.js版のツールです。ローカルで使うNode.jsのバージョンを簡単に切り替えることが出来ます。
git clone <https://github.com/nodenv/nodenv.git> ~/.nodenv
nodenv にパスを通します。
echo 'export PATH="$HOME/.nodenv/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(nodenv init - bash)"' >> ~/.bashrc
source ~/.bashrc
Node.js をインストールして、nodeenvに登録を行います。
git clone \
https://github.com/nodenv/node-build.git \
"$(nodenv root)"/plugins/node-build
curl -fsSL \
https://github.com/nodenv/nodenv-installer/raw/main/bin/nodenv-doctor | bash
# インストール可能なバージョン確認
nodenv install --list
# v20など、LTSの最新バージョンをリストの中から確認
nodenv install 20.17.0
nodenv global 20.17.0
node -v
npm -vまとめ
以上が弊社でよく行っているAmazon Linux 2023を使ったPythonの開発環境設定手順になります。このガイドでは開発用のEC2の設定からPythonやNode.jsのインストール及び必要なツールについてのインストール方法について解説しました。特にAIや機械学習関連のプロジェクトにおいては、最新のツールやライブラリを利用しながら、安定した環境を整えることが重要です。今回の手順を参考にして、効率的で安全な開発環境を構築するようにしましょう。