

前回の記事(「LangChain + Amazon Bedrock + Momento で構築する、AWSフルサーバーレスRAG構成のすすめ(1)」)では、固定費ゼロの構成で RAG 構成を実現すべく、テキストファイルを読み込んで、分割と Embedding 処理を行った上で、QA 形式で回答を叩き出す方法についてお伝えしました。続いて、今回も固定費が一切かからない、完全サーバーレスな RAG 構成を目指したもう一つの構成をご紹介したいと思います。
タイトルからお分かりになると思いますが、Amazon Bedrock には Knowledge base というサービスがあります。前回 LangChain を使って Embedding を行い、その結果を Vector Store に保存するような一連の仕組みをコンソールのみで実現することができるサービスで、非常に使いやすく、RAG 構成の基本的なパーツをノーコードで作ることができるためオススメです。データソースとなる S3 バケットを指定して PDF などのファイルをアップロードしておけば、テキストの抽出から Embedding まで一通りマネージドで行ってくれます。
※取り込みデータの種類についてはこちらの公式ドキュメントも合わせてご参考ください。
実は、少し前まで、Knowledge base の Vector Store として利用できる連携サービスの中で、従量課金を基本とするサーバーレスな料金体型の選択肢はありませんでした。しかし、Pinecone というサービスからサーバーレスな料金体型が Public Preview としてアナウンスされており(2024/01/16)、この料金体型であれば、Knowledge base を使った構成でも従量課金を基本とする完全サーバーレス化が可能になっています。具体的には、こちらの記事で詳細を確認できます。この記事では、Amazon Bedrock + Knowledge base + Pinecone を使った RAG 構成の構築方法と、アプリに組み込むための LangChain サンプルコードについて紹介していきます。
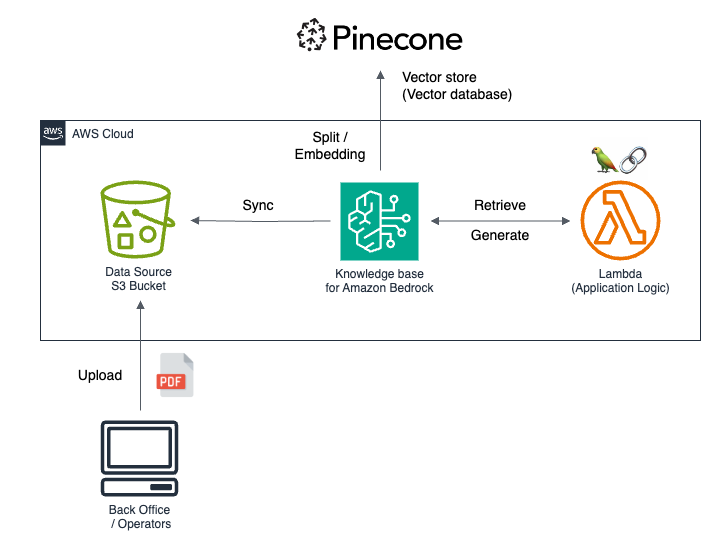
構成の概要
構成要素は多くなく、RAG の基本構成に合わせてシンプルな形にお落とし込める形になります。
Pinecone アカウント作成および Serverless Pricing の登録
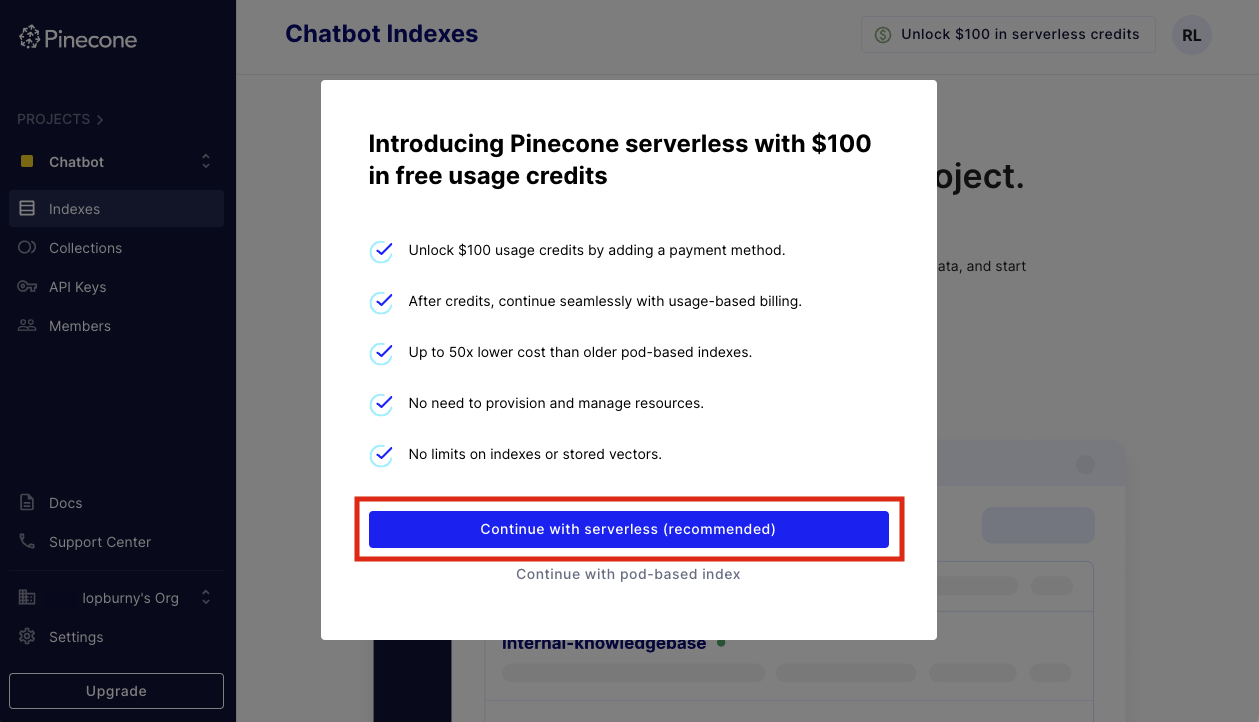
まずは Pinecone のアカウントを登録してダッシュボードに移動すると、以下のように Serverless 課金で $100 クレジットがもらえる旨のダイアログが表示されます。推奨の Serverless ボタンを選択します。
その後、お支払方法を登録する画面になります。カード情報を登録しても良いですが、AWS Marketplace で連携して AWS アカウントから課金されるようにしておくと便利です。SaaS Subscription 型として出店していて、利用した分のユニット数が精算されて AWS の Billing ダッシュボードから確認できるようになります。
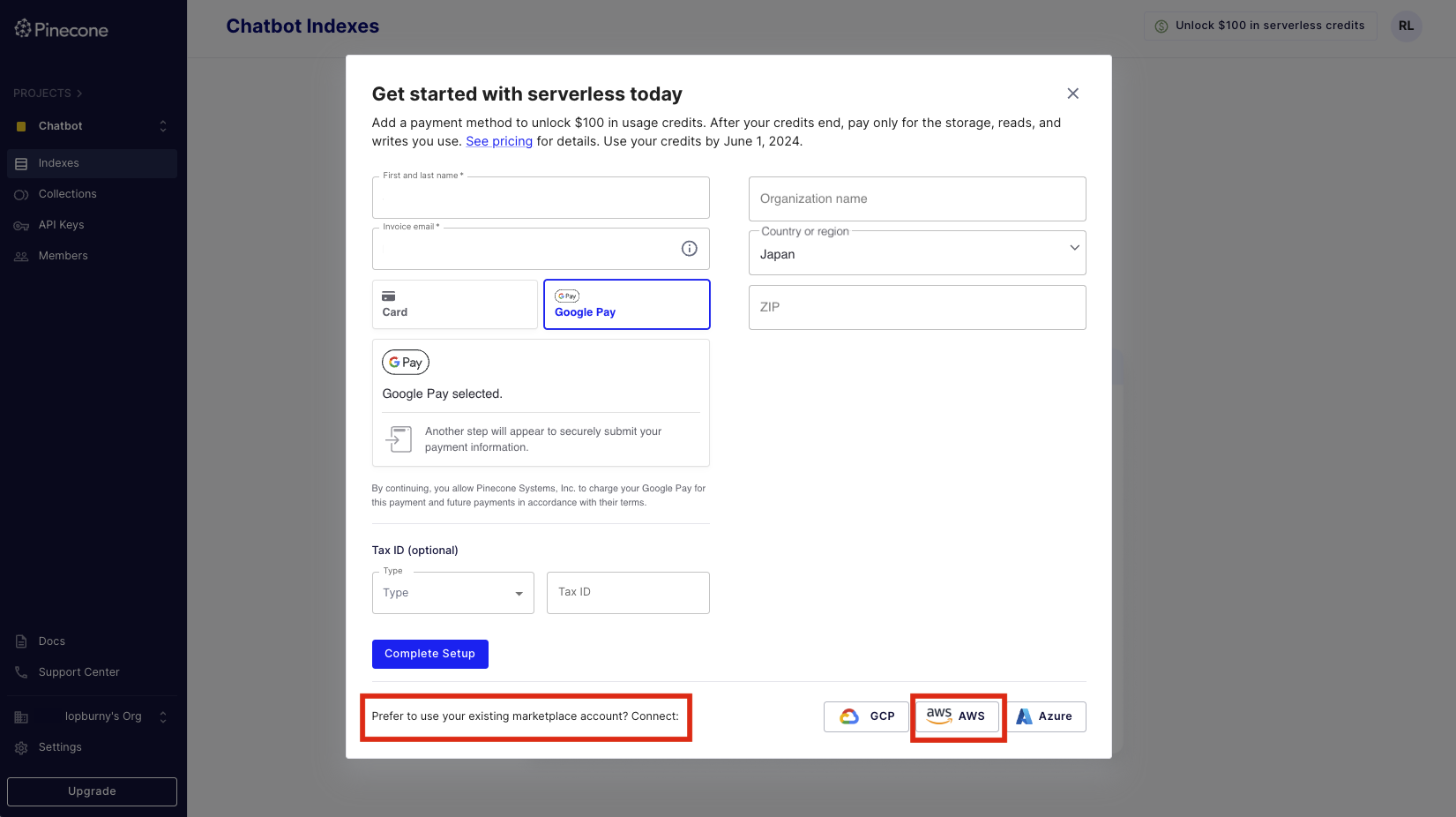
※AWS Marketplace - SaaS Subscription の仕組みについて、詳細が気になる方はこちらの記事も合わせてご参考ください。
AWS Marketplace から購入オプションを確認します。
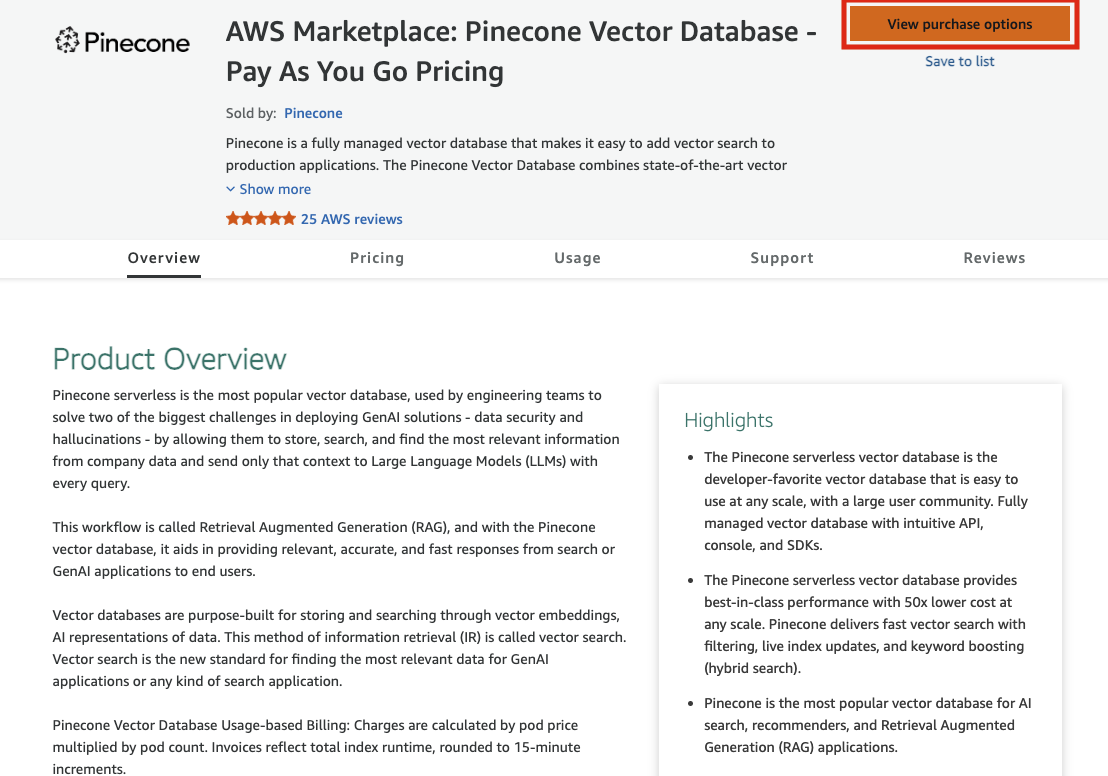
料金を確認した後 Subscribe ボタンを押すと、Pinecone ユーザー認証を再度行い、Marketplace に連携された状態の Organization が作られます。組織が変わったことを確認して、インデックスを作成します。
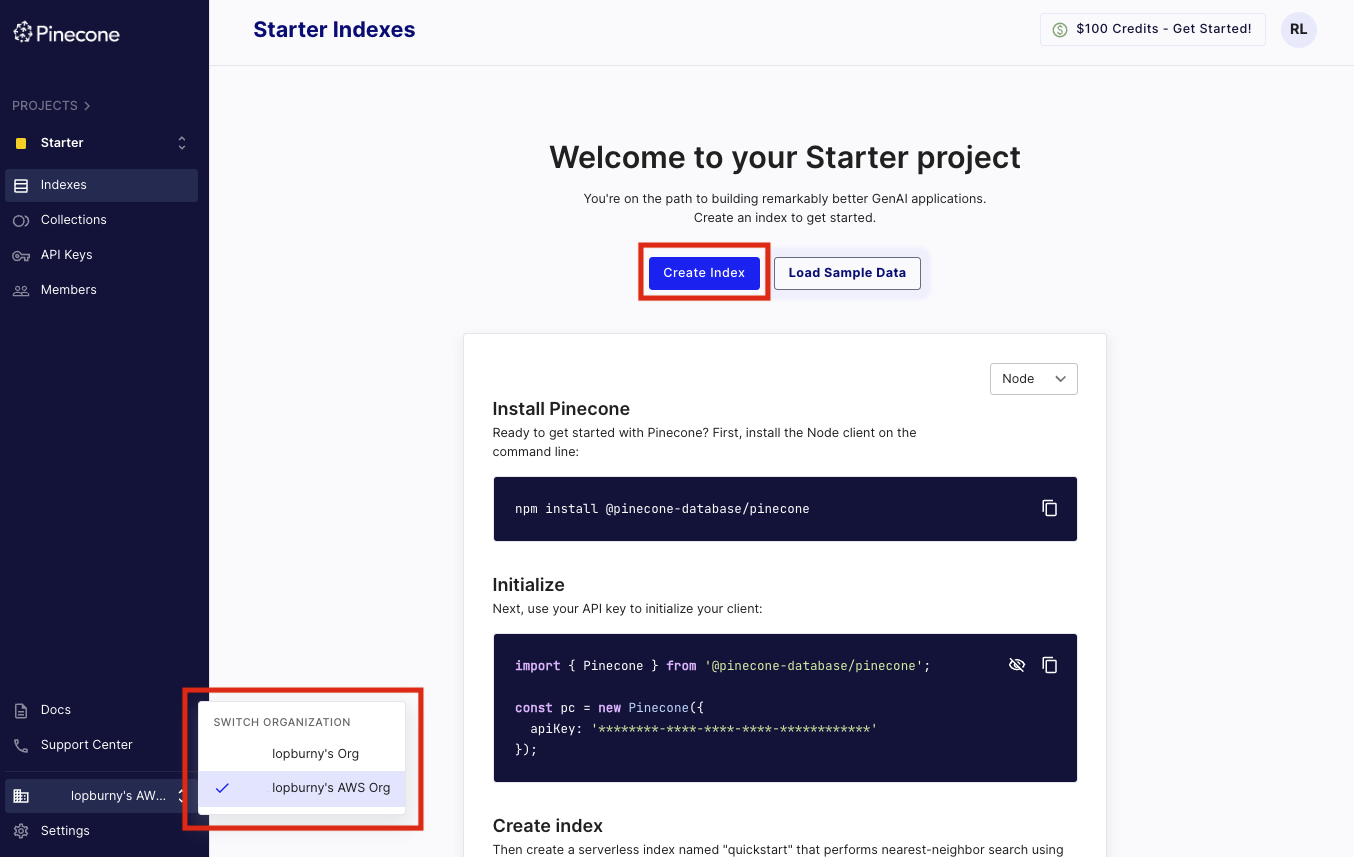
Pinecone のインデックス作成
インデックス作成画面に進み、以下のようにインデックス名と設定項目を入力して作成を進めます。Knowledge base で利用する際の各設定項目の詳細については、公式ドキュメントも合わせてご参考ください。
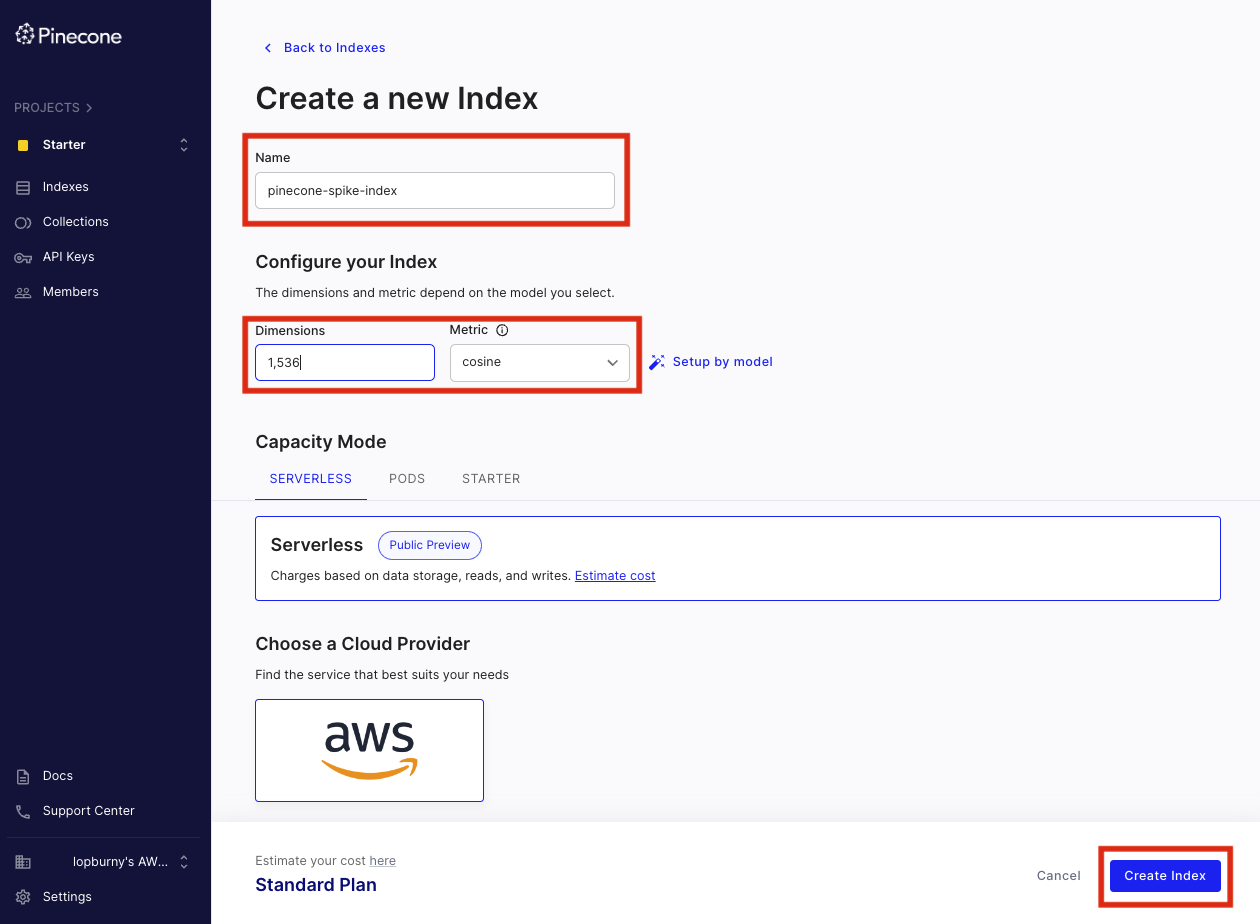
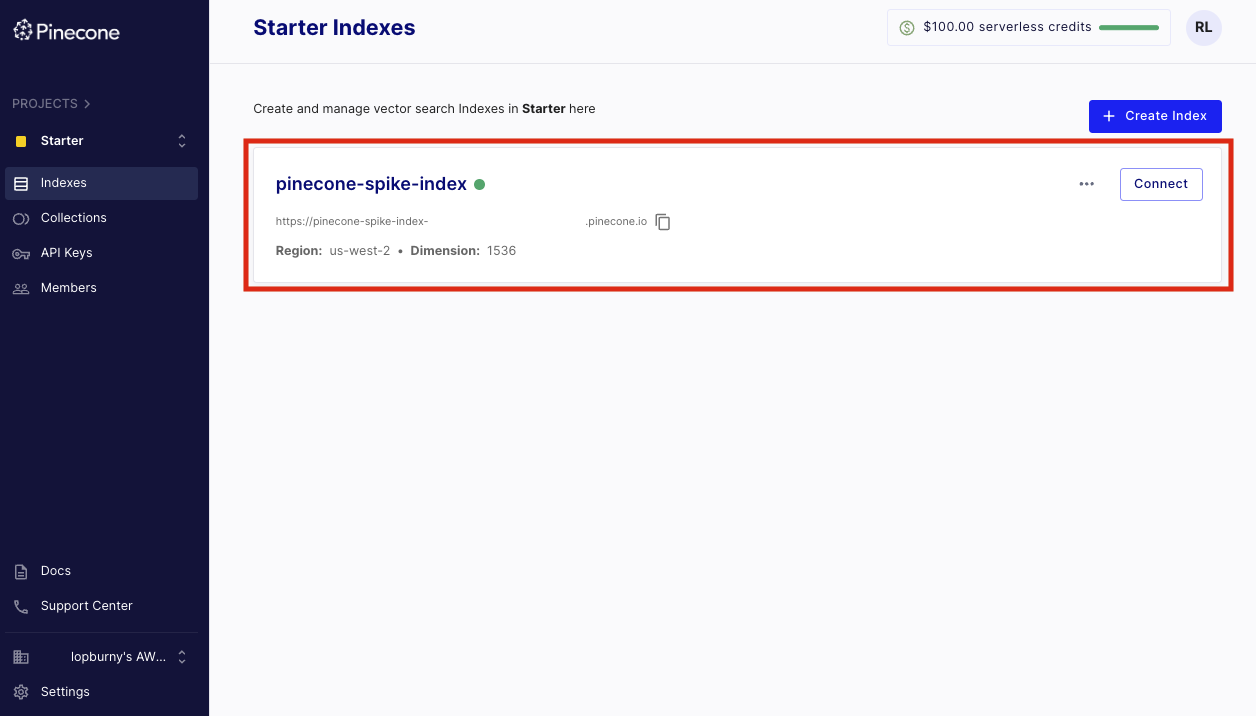
インデックスが作成できたら、以下のように表示されます。クリックすると接続のためのホスト名などの情報が表示されているので、後ほど Knowledge base 作成時に利用します。Pinecone の設定は一旦この状態で完了となります。
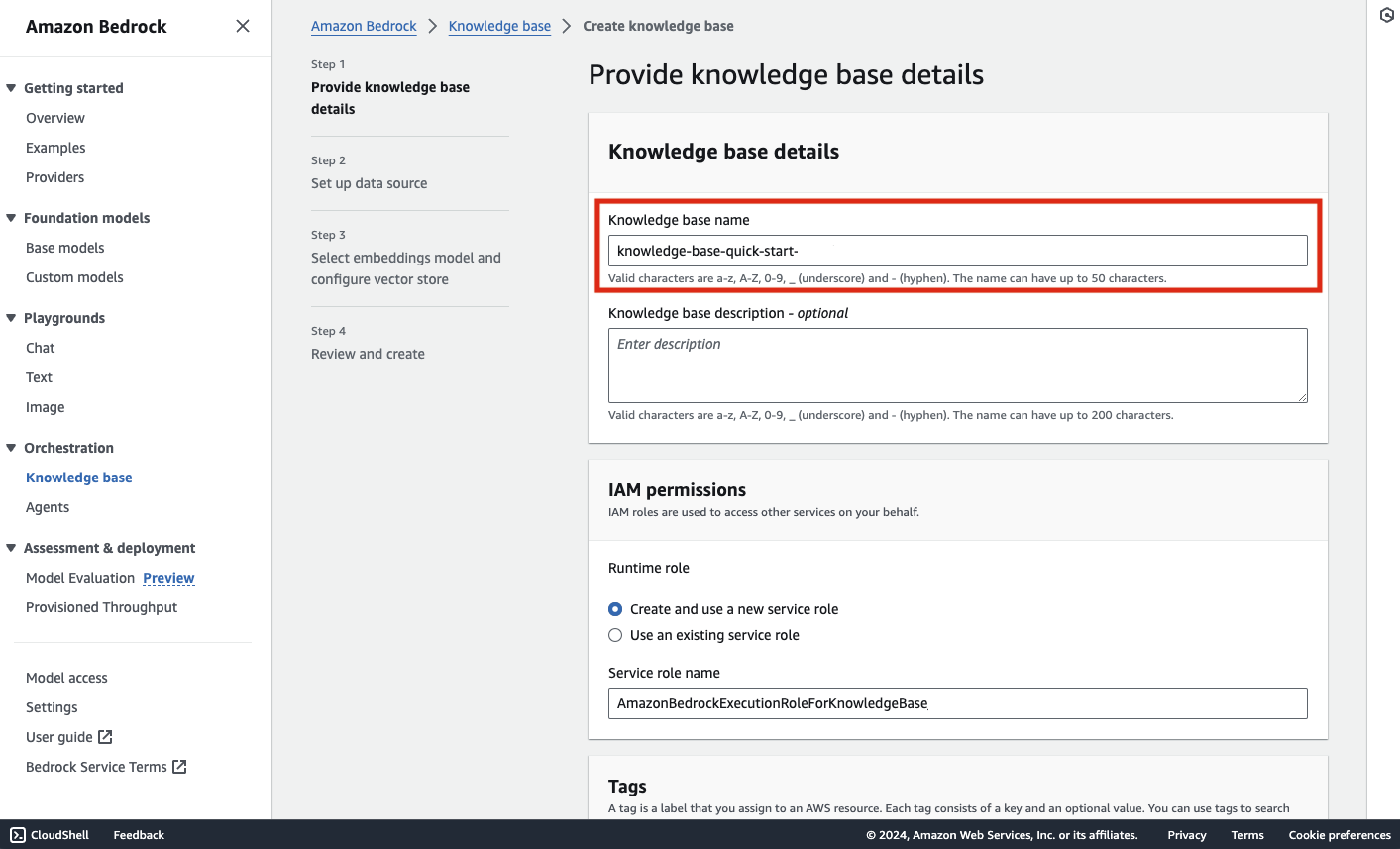
Knowledge base の作成
続いて、Bedrock のコンソールを開き、左側メニューから Knowledge base を選択、リソースを作成していきます。作成するリージョンはこの記事の公開時点(2024/01/29)で us-east-1 がおすすめです。
続いてデータソースとなる S3 バケットを指定します。こちらで指定する S3 バケットに PDF などのファイルをアップロードすることになります。
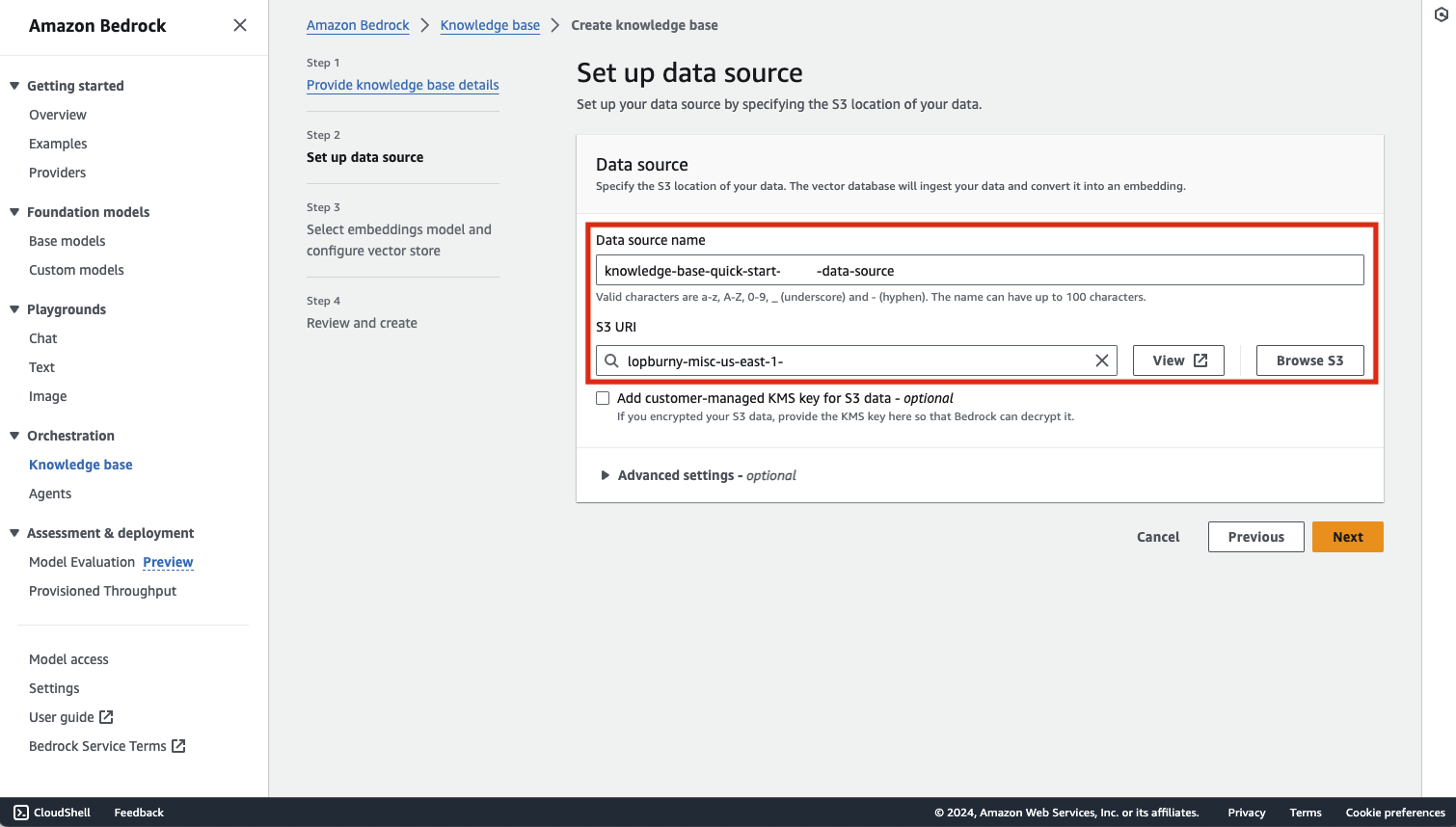
Embedding で利用するモデルを選択します。前回の記事同様、「Titan Embeddings G1 - Text v1.2」を選択します。
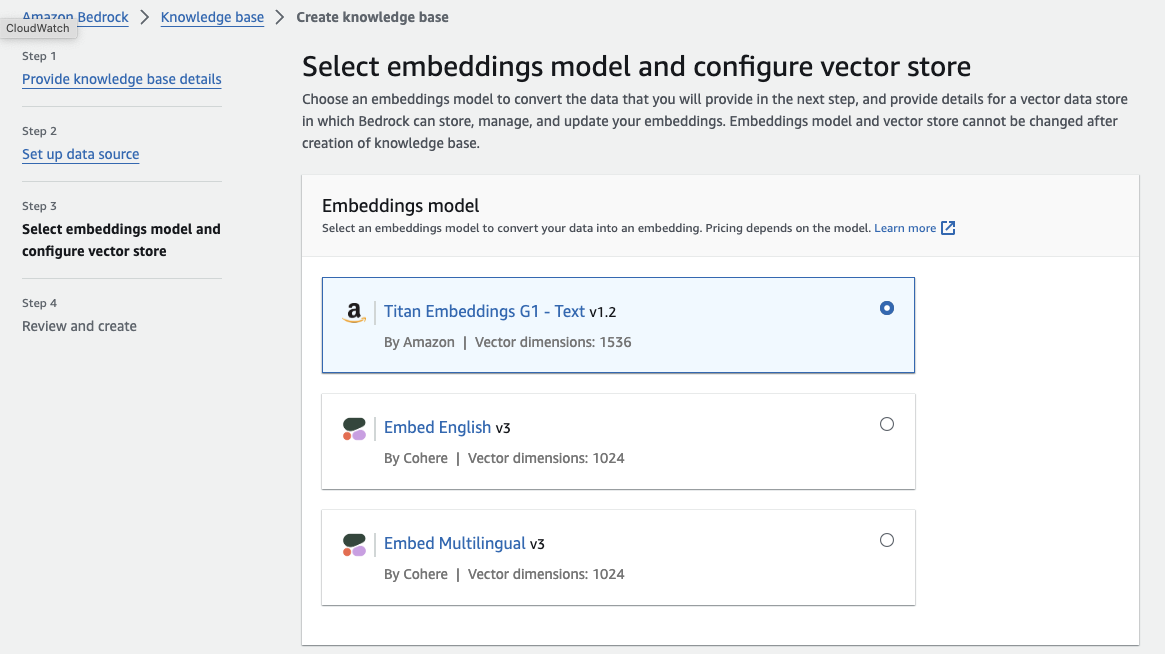
Vector database を選択します。記事作成時点(2024/01/29)では、他の3つの選択肢が Hourly ベースの時間課金であることに対して、固定費が発生しない従量課金の選択肢は Pinecone のみになります。

Pinecone を選択すると以下のような入力項目が表示されます。「Connection string」には、Pinecone のコンソールから作成したインデックス画面「host」の値をセットします。また「Credentials secret ARN」に関しては、Pinecone のコンソール左側メニュー「API Keys」から取得した値を Secret Manager に登録し、その ARN を指定する必要があります。Metadata field mapping については適宜以下のように値を入れてください。
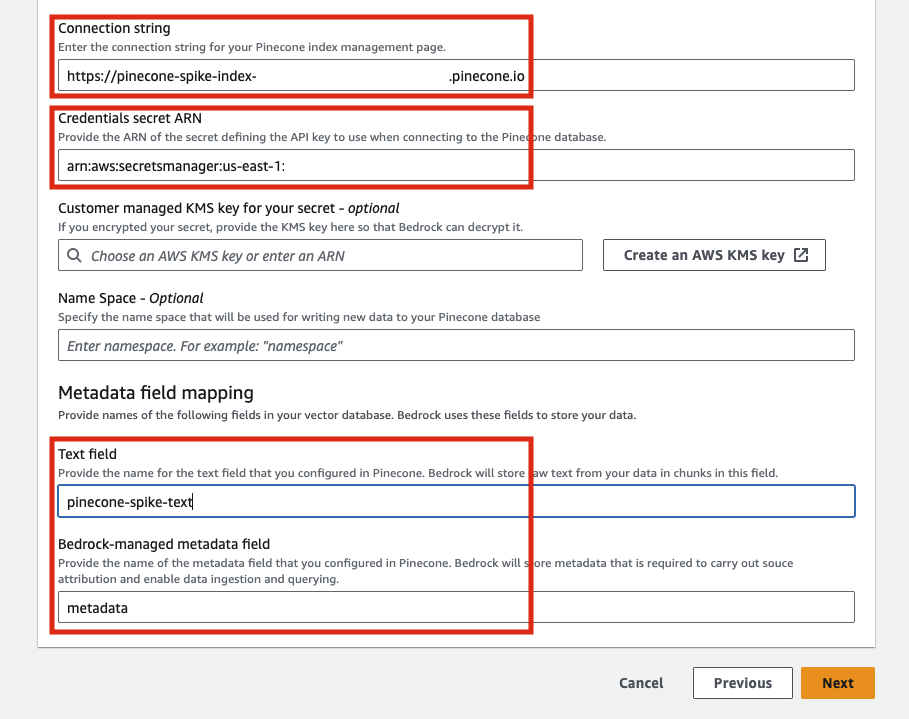
Secret Manager に API Key を指定する時は、以下のように「apiKey」というキーを指定しないとエラーになるので注意してください。
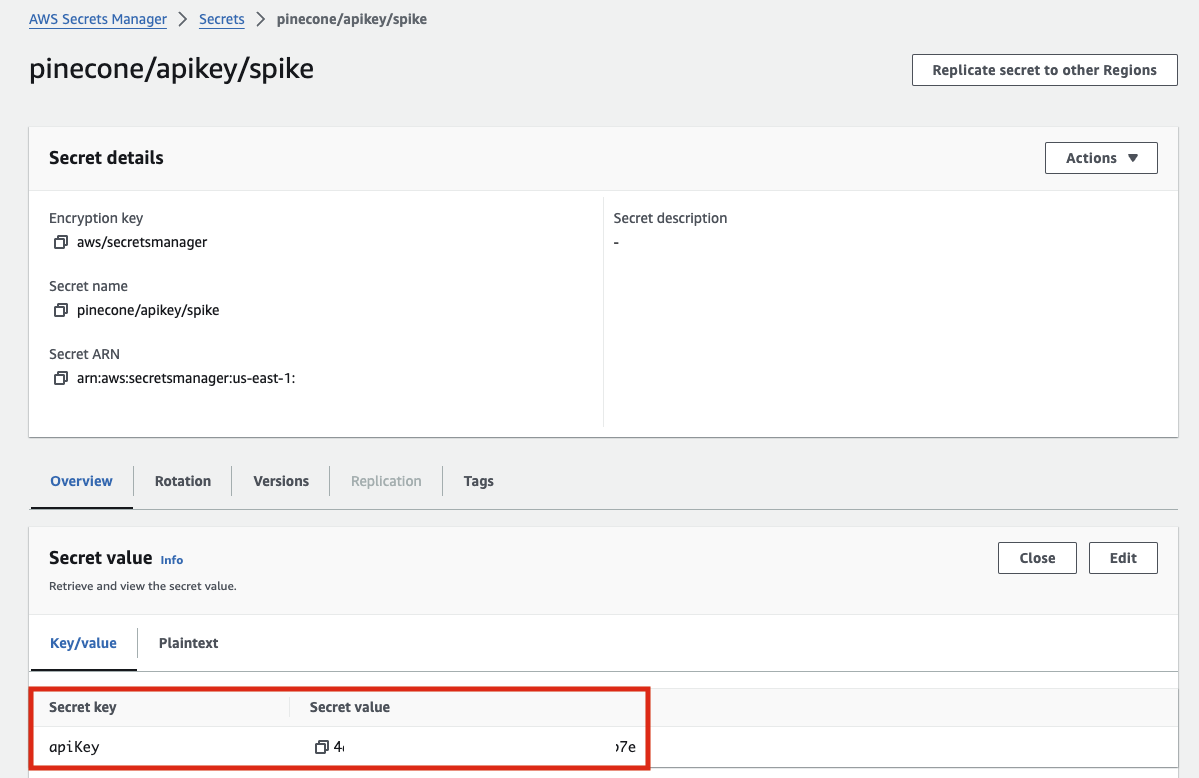
無事に登録できれば、以下のような画面になります。ソースデータを投入すれば右側の Test knowledge base からすぐにチャットで質問をすることができますので、生成モデルは前回同様 Claude を選択し、S3にデータを投入してみます。
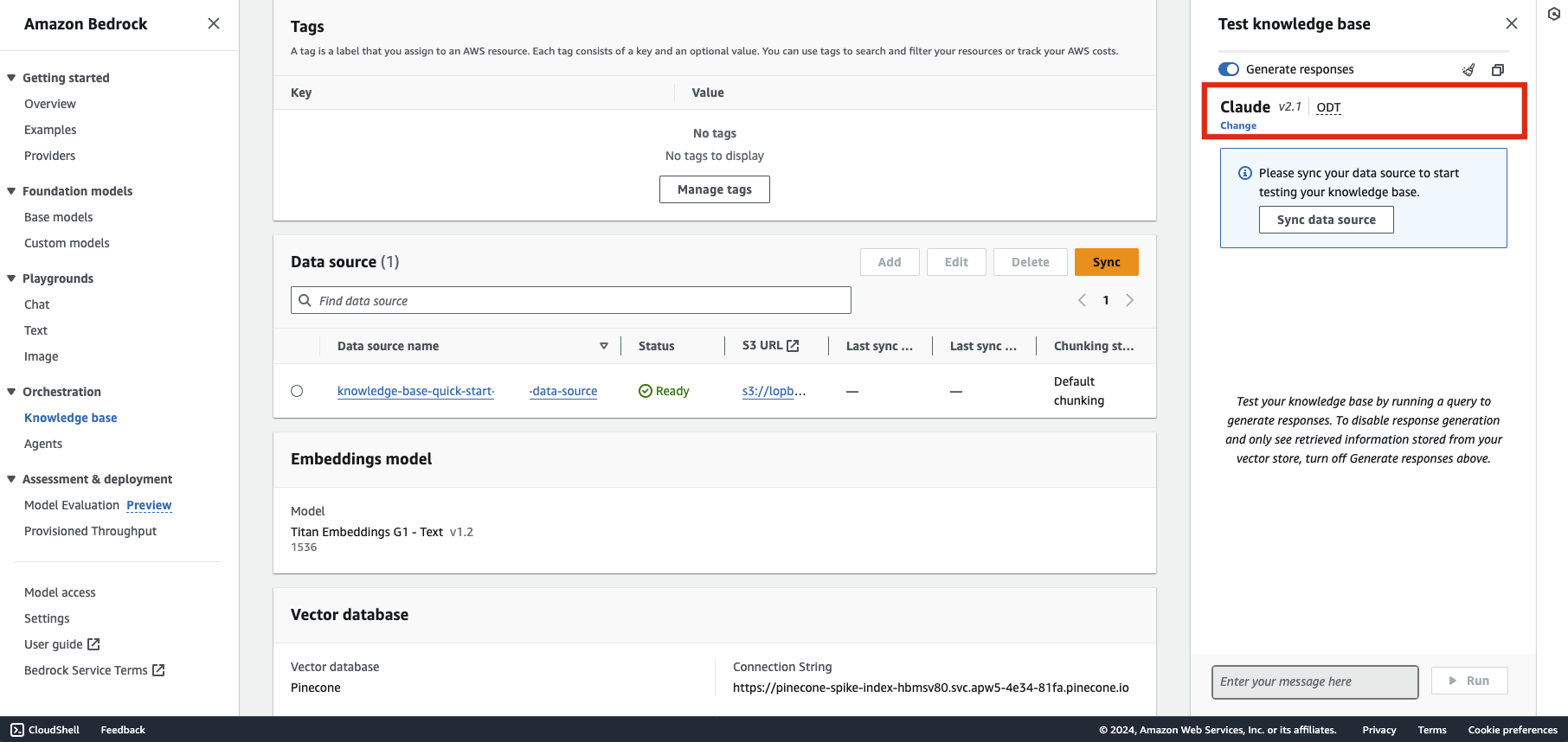
読み込むPDFデータを登録、テストする
実際に RAG 構成の動作を確認するため、簡単な質問が行える資料を投入してみることにします。今回はサンプルとして、気象庁が発行する「週間天気予報解説資料」をダウンロードして S3 にアップロードしておきます。

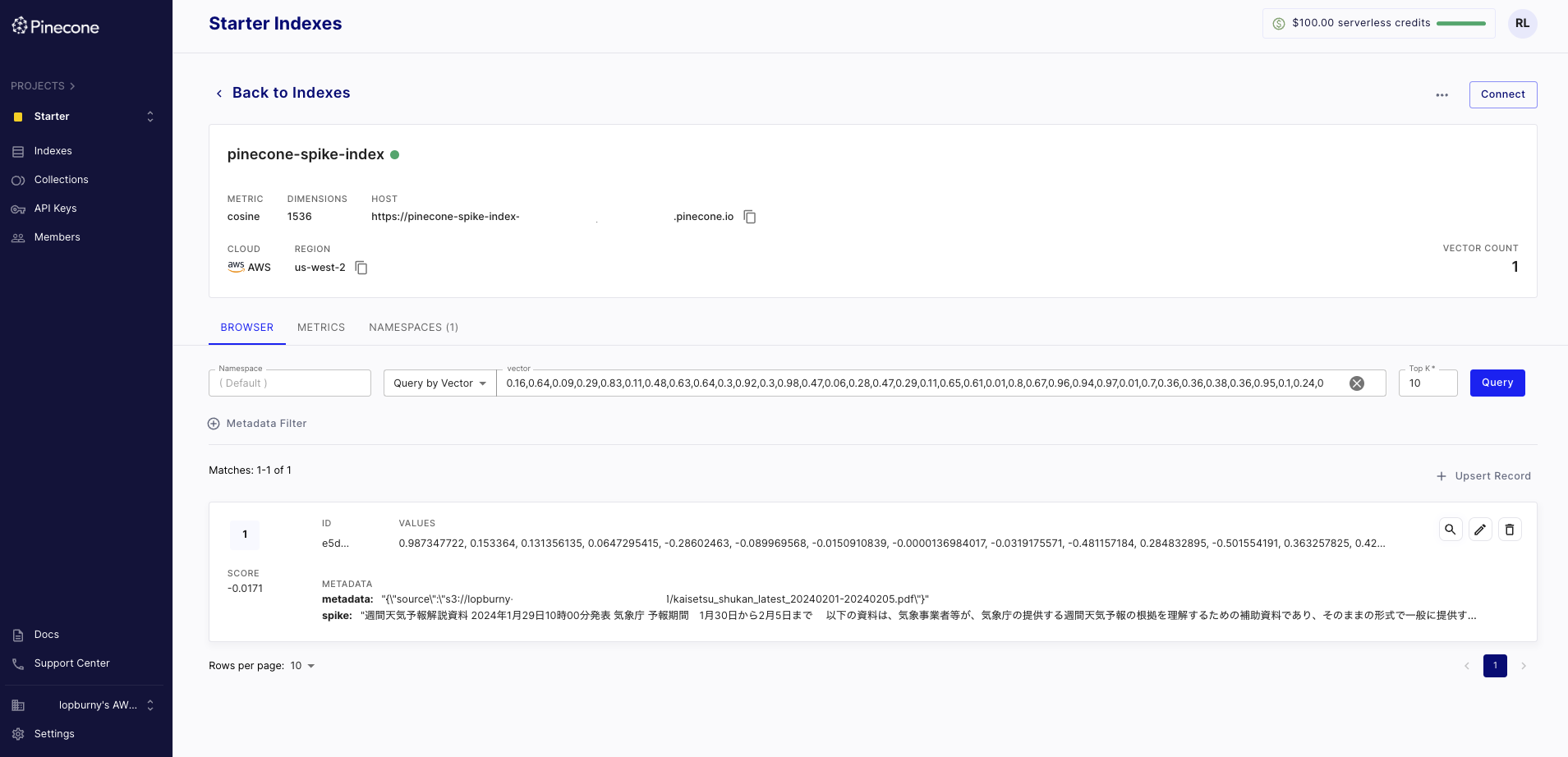
先ほどの Knowledge base コンソールから同期(Sync)ボタンをクリックしてしばらくすると、同期が完了します。Pinecone のコンソールから確認すると以下のように Embedding されたベクトルデータを確認することができます。
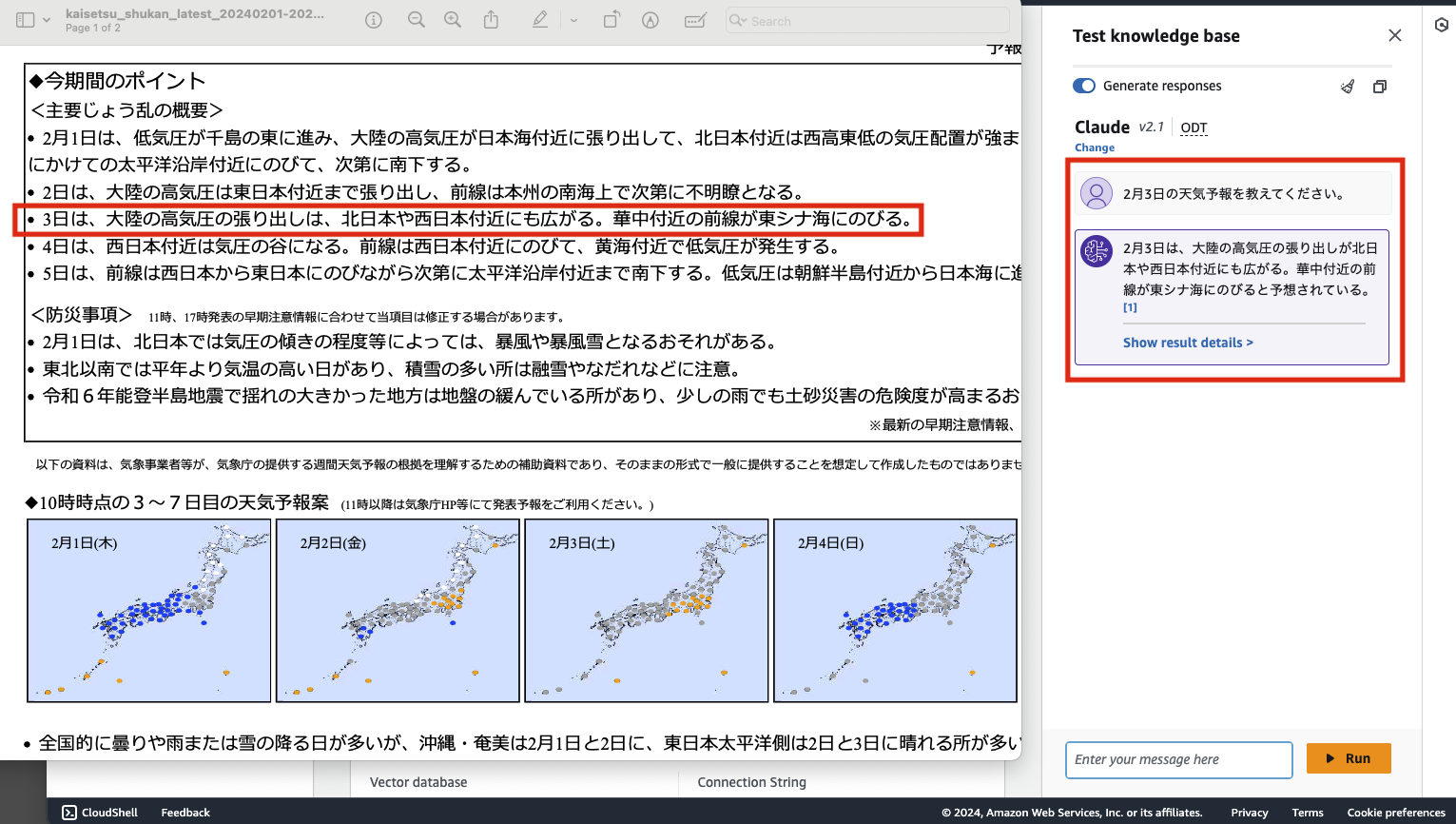
Knowledge base コンソール → Test knowledge base から実際に質問を投げてみると、ちゃんと登録したデータを元に回答が生成されていることが確認できます。
LangChain を使ってアプリから Knowledge base に繋いで回答を生成する
Knowledge base を使って Vector Store に保存されているデータを元に回答を生成する機能が試せたので、実際のアプリケーション開発で適用してみます。前回の記事同様、LangChain の RetrievalQA を利用して回答を叩き出します。具体的には、以下のように langchain_community から AmazonKnowledgeBasesRetriever という retriever をインポートして利用する形です。
from langchain_community.retrievers import AmazonKnowledgeBasesRetriever
# ...
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id="knowledge_base_id",
retrieval_config={
"vectorSearchConfiguration": {
"numberOfResults": 4
}
}
)以下、質問と回答を含めたサンプル実装と解説です。Embedding のコードが必要なくなったので、クライアント側の生成部分が対象になります。
import boto3
from langchain_community.retrievers import AmazonKnowledgeBasesRetriever
from langchain_community.llms import Bedrock
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from prompts import prompt_template_qa, prompt_template_qa_ja
# 前回の記事と同じです。
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
llm = Bedrock(
client=boto3.client("bedrock-runtime", region_name="us-east-1"),
model_id="anthropic.claude-v2",
model_kwargs={"temperature": 0.0, "max_tokens_to_sample": 500},
)
# retriever は AmazonKnowledgeBasesRetriever を import してきて利用します
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id="knowledge_base_id",
retrieval_config={
"vectorSearchConfiguration": {
"numberOfResults": 4
}
}
)
# 前回の記事と同じです。プロンプトは適宜調節を行なってください。
prompt_qa = PromptTemplate(
template=prompt_template_qa_ja,
input_variables=["context", "question"]
)
# 前回の記事と同じです。
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff',
retriever=retriever,
chain_type_kwargs={"prompt": prompt_qa}
)
result = qa.invoke('2月3日の天気予報について教えてください。')
print('## result', result)
## result {'query': '2月3日の天気予報を教えてください。', 'result': ' 2月3日の天気予報は以下の通りです。\n\n- 大陸の高気圧の張り出しが、北日本や西日本付近にも広がる\n- 華中付近の前線が東シナ海に伸びる'}終わりに
この記事で述べてきたように、Knowledge base を使えば RAG 構成を比較的簡単に立ち上げることができます。あとは適宜クライアント実装を行うだけですぐにアプリ開発が行える、サーバーレスらしい仕組みだと言えるのではないでしょうか。固定費のない完全従量課金モデルのVector Store ソリューションの選択肢も広がっていますので、今後も更なる盛り上がりや便利な仕組みが登場することが予想されます。ぜひ皆さんもチャレンジしてみてはいかがでしょうか。