

前編の記事にてRDSとDynamoDBのデータベースとしての特徴の違いから、どのように選定を行えばよいのかを説明しました。
本記事では後編として、それ以外の観点での使い分けについて述べていきたいと思います。
サーバーレスの良さを活かすならDynamoDB
サーバーレスの良さとして、サーバーなどのインフラメンテナンスをクラウドにアウトソーシングし、ユーザは開発に集中できる点があります。
DynamoDBでいうと、以下のような点です。
- 冗長化をユーザ側で行わなくて良い。データは自動で3箇所のデータセンターにコピーされる
- 容量は無制限
- インスタンスのサイジングは不要
- VPC = ネットワーク設計を行う必要がない
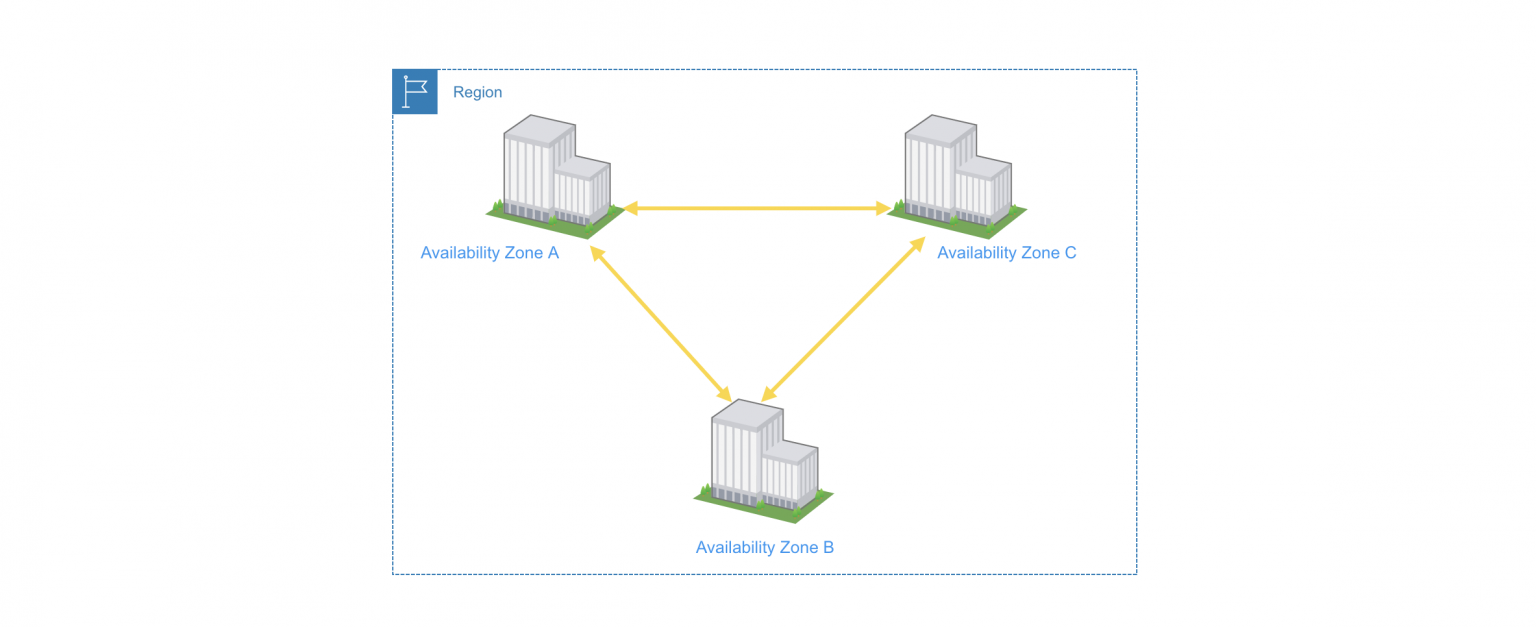
RDSを使用する場合、初期構築の段階でVPCによるネットワーク設計・構築やインスタンスのサイジングが必要になりますが、DynamoDBの場合はそれらは不要です。
運用においても、OSのパッチ適用のような定期メンテナンスは、AWSが知らない間にやってくれます。そして、テーブル設計が正しく出来ている前提ではありますが、データの容量やトラフィックが大きく増えてもパフォーマンスが落ちることはありませんし、それに対応するためのシステム運用は発生しません。
多くの人が扱いやすいのはRDS
多くの開発者が普段から使い慣れているのはやはりRDSでしょう。プロジェクトを開始して、開発者を募集したとします。その際にRDSを選定していたほうが開発者は集めやすいでしょうし、いい意味で枯れた技術でもあるためアプリケーション開発の目的のためにはフィットしやすいのではないでしょうか。
テーブル設計
DynamoDBのテーブル設計は以下のようなポイントに基づいて行います。
- アクセスパターンをベースにしてデータモデリングを行う必要がある。RDSのようにエンティティを抽出して正規化を行うという手順は踏まない
- 各パーティションにデータが分散するキー設計。ホットパーティションを発生させない
- 読み込みや検索はGSIで表現する。GSIで対応しきれないケースは別テーブルに専用のデータを作るのもあり
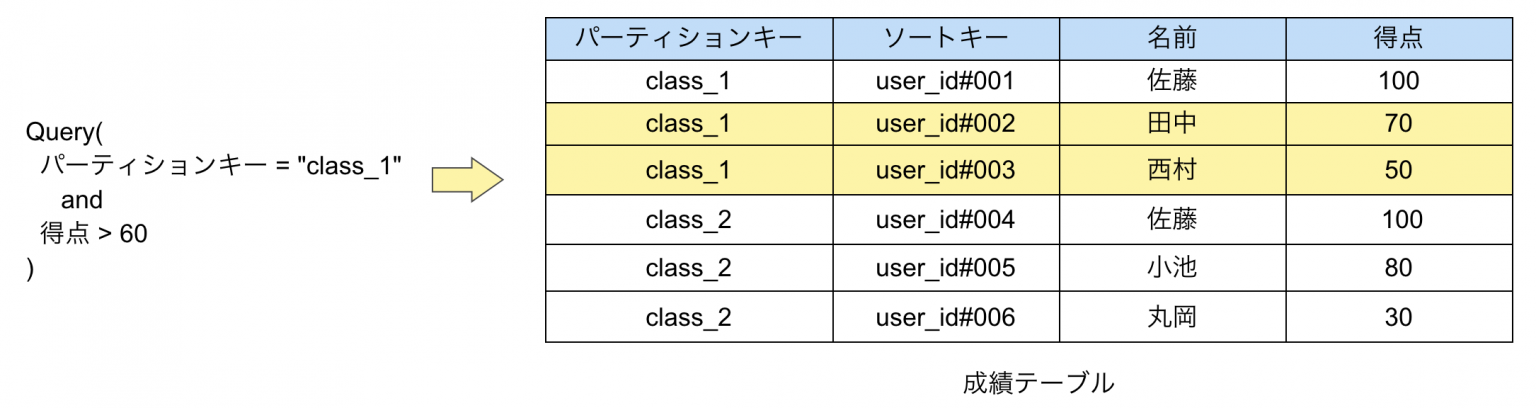
スキーマレスDBであるDynamoDBの特性を考えると、正規化を行なってテーブルを設計する必要性はありません。アクセスパターンに基づいてデータモデリングを行なうことが重要になります。
しかし、RDSに慣れ親しんだ開発者にとって、このあたりの学習コストが高いと感じる人も多いでしょう。
検索
DynamoDBは検索が苦手とよく言われます。これはDynamoDBの構造上、パーティションをまたいでインデックスを構成することが出来ないことに要因があります。パーティションをまたいでインデックスを構成するということは1つの共有ストレージの中でインデックス空間を構成することになります。これでは、膨大なデータ量や大量のトラフィックを捌く上でのボトルネックになり得てしまいます。
なのでDynamoDBは、性能を優先させた結果、検索のしやすさを捨てているというわけですね。
ただ、検索が出来ないというわけではなく、各パーティションではインデックスが構成されているのでパーティションキーを指定した上での検索は出来ますし、GSIを構成したり、検索専用のテーブルを作ると行った形でも対応することは可能です。また、そのレスポンスタイムやコストが許容できるデータ量であるならば、割り切ってフルスキャンを行うことも1つの手です。betweenやcontains, begins_withといったフィルタ式を使うことで、範囲検索や部分一致、前方一致などの検索も可能です。
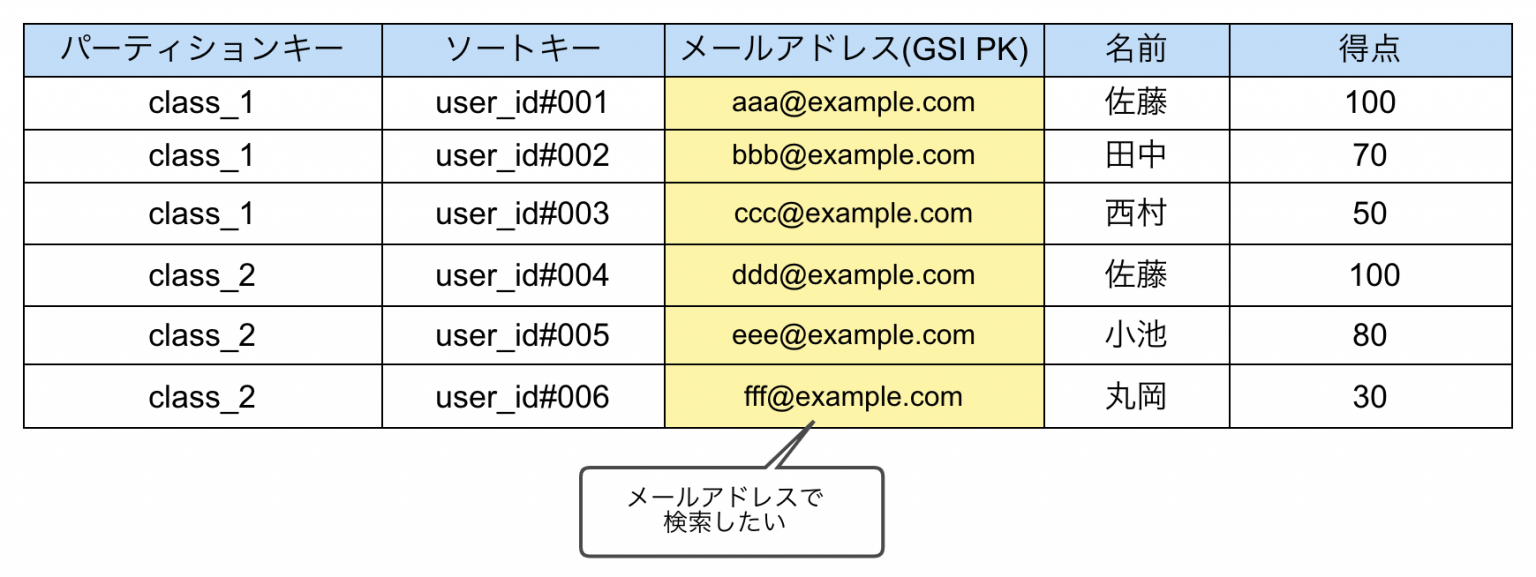
しかし、やはりRDSに比べて検索が扱いづらいというのは多くの人が感じることでしょう。
ハイブリッドな構成もあり
DynamoDBとRDSを一緒に使ってお互いのメリットを活かすという構成もケースによっては有りです。
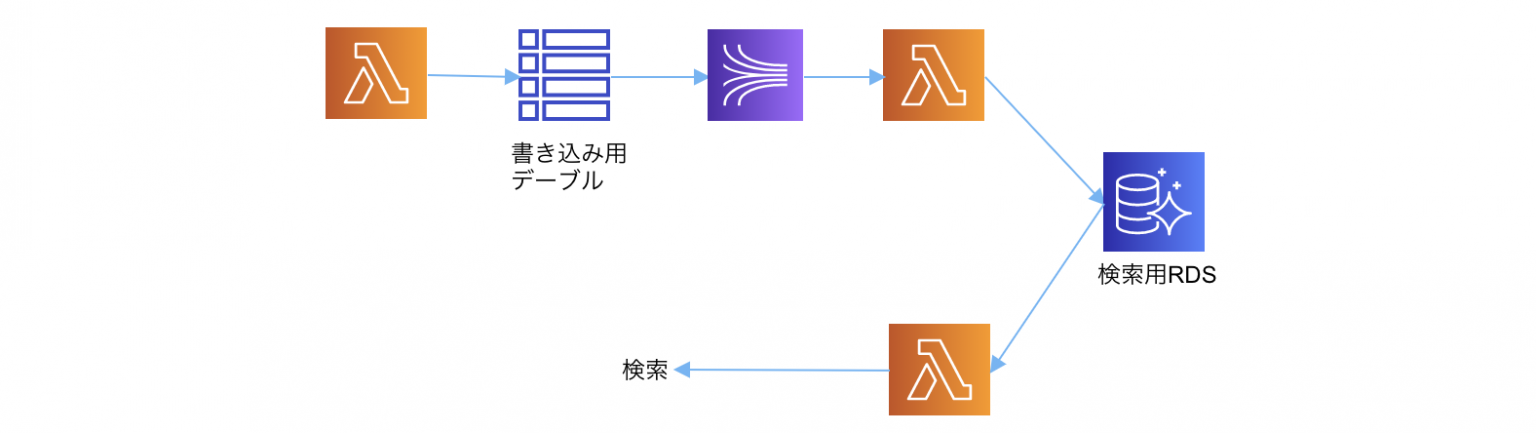
例えばハイトラフィックなアクセスがあり、さらに複雑な検索も発生する場合はこれが有効です。その場合はオンラインでのトラフィックをDynamoDBで捌き、DynamoDB Streamを使って非同期でRDSにデータを登録、後から読み込み・検索用のDBとしてRDSを取り扱うことも出来ます。